2021. 10. 31. 02:34ㆍ논문리뷰/Etc
지난 번에 이어서 계속 리뷰를 해보도록 하겠다!
이전 리뷰를 안봤다면 먼저 보고오도록!!

https://aistudy9314.tistory.com/47
[논문리뷰] Deep Image Prior(1)
이번에 소개할 논문은 Deep Image Prior라는 제목의 paper이다. 이 논문을 읽었을 때, 기존 딥러닝에 대한 고정관념이 '팍' 깨지는 느낌이 들었다. 그만큼 singular한 논문이었고, 심지어 결과도 잘 나오
aistudy9314.tistory.com
지난번 마지막 파트에서 CNN Architecture의 파라메터 $\theta$를 반복적으로 업데이트 시킴으로써 clean한 이미지를 얻을 수 있다라는 Deep Image Prior Method의 전체 flow를 보았다.
일반적으로 생각하였을 때, Noisy Image와의 loss를 가지고서 clean image를 얻어내는 것은 무언가 부자연스러울 수 있다.
1. Impedence to noise
이 논문에서는 다음과 같은 실험을 한다.
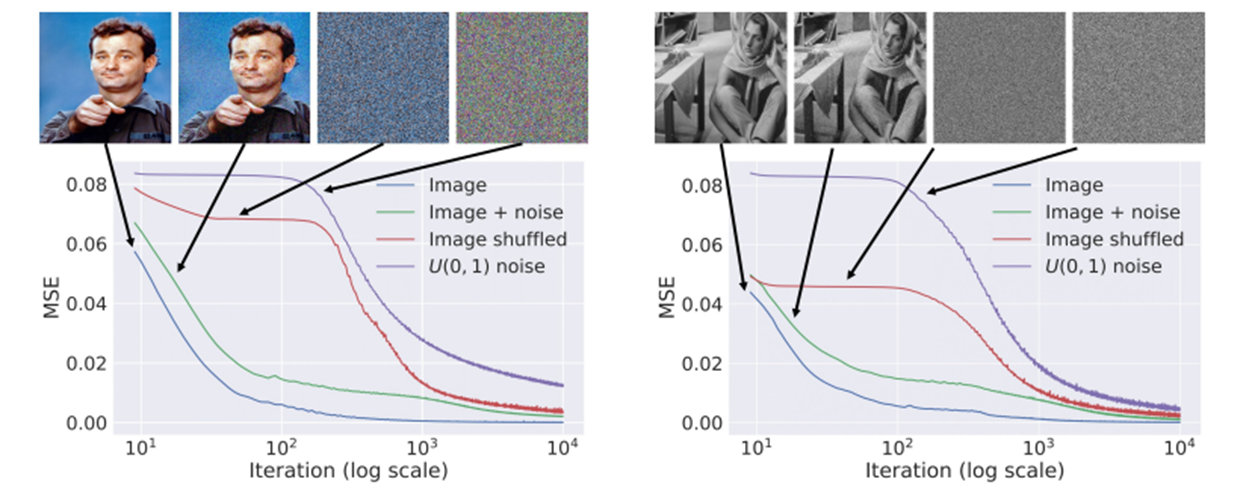
그래프의 경향과 legend를 살펴보면 어떠한 실험과 비슷하다는 것을 금방 눈치챌 것이다. 그렇다 random label!! 이전 포스트에서 설명하였던 실험이다. 여기서는 clean image와 image+noise, image의 pixel들을 shuffle해놓은 이미지, Uniform noise 4개의 이미지에 대해서 실험을 한다.
그래프를 보면 똑같이 매우 많은 iteration을 학습하게 되면 결국에는 데이터가 모델에 피팅되는 것을 알 수 있다. 하지만 이 논문에서는 이렇게 noise가 fitting되는 것이 부자연스러워 보인다! 라는 말을 하는 것이다.
그래프를 살펴보면, clean한 이미지에 대해서는 빠르게 converge가 일어나고, image+noise은 좀 더 느리게 image shuffled 데이터와 uniform noise는 매우 느리게 converge되다가 어느 순간에 훅 떨어지는 것을 볼 수 있다.
이 결과를 보고 어떤 생각이 드는가?
논문에서는 noise에 high impedence를 가지고 있다라고 주장한다. 즉, noise가 심한 데이터일수록 모델에 fitting되는데에 있어서 저항도 커진다는 것이다. 매우 큰 iteration에 대해서 어느 순간 급격하게 loss가 떨어지는 구간은, architecture가 noise에 fitting되기를 거부(저항)하다가 견디지 못하고 부자연스럽게 fitting이 되버린것이라고 생각할 수 있다.
즉, 이 급격하게 떨어지는 절벽 이전의 the best iteration point에서 update를 멈춘다면 noise에 fitting된 image가 아닌 clean한 이미지를 얻을 수 있다는 결론이 나온다.
2. Two Updating Case
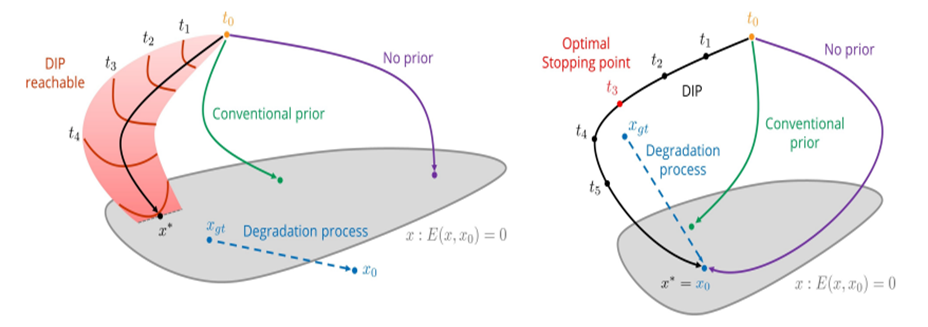
Model의 파라메터 update가 이루어지는 case를 2가지로 나누어 볼 수 있다.
왼쪽 이미지는, 최적의 case로써 iteration을 매우 크게 돌리더라도 최종 prediction 이미지가 ground truth(clean image)와 매우 근접한 경우이다. 즉, optimal stopping point를 따로 찾아주지 않아도 된다.
오른쪽 이미지는, iteration을 너무 크게 돌리면 ground truth와 가까운 지점을 지나쳐서 degraded image로 fitting 되버리는 경우이다. 이 경우에는 optimal stopping point를 찾아서 early stopping을 통해 clean image를 얻을 수 있다.
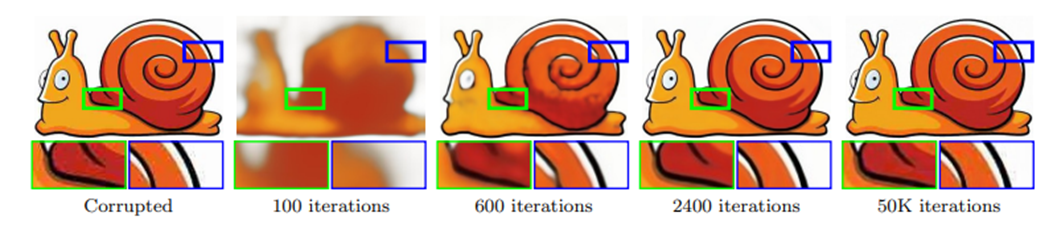
위 이미지가 early stopping이 필요하다는 예 중 하나인데, 이게 정말 자세히 보지 않으면 알 수 없다....2400번째가 clean image, 즉 optimal stopping point에서 멈춘 결과이고 50000번째가 noise에 fitting된 이미지이다. 자~~~~~~`세히 살펴보면 corrputed image와 비교하여 2400이 조금 더 깔끔하고 50000은 완전히 동일한 것을 알 수 있다.
Ealy Stopping
저자가 말하기를 early stopping이 필요한 task로는 denoising, super-resolution, image enhancement정도가 있다. 그리고 이 early stopping을 어느 iteration에서 할 것인가도 문제인데, 저자는 task마다 이 optimal stopping point를 찾아주진 않았고, 2000번에서 2400번 정도의 iteration으로 고정시켜서 실험하였다고 한다. (2000~2400사이면 최적 point를 찾을 수 있는것인지 아니면 data dependency한 것인지...약간 대답이 애매....)
3. Application
이제 실제로 각 task마다 Deep Image Prior가 적용되는 것을 살펴보자.
3.1 Denoising
Noisy Image(X') = Clean Image(X)+ noise($\epsilon$)
보통 training method에서는 noise $\epsilon$이 어떠한 distribution으로 표현된다(ex. Gaussian Noise).
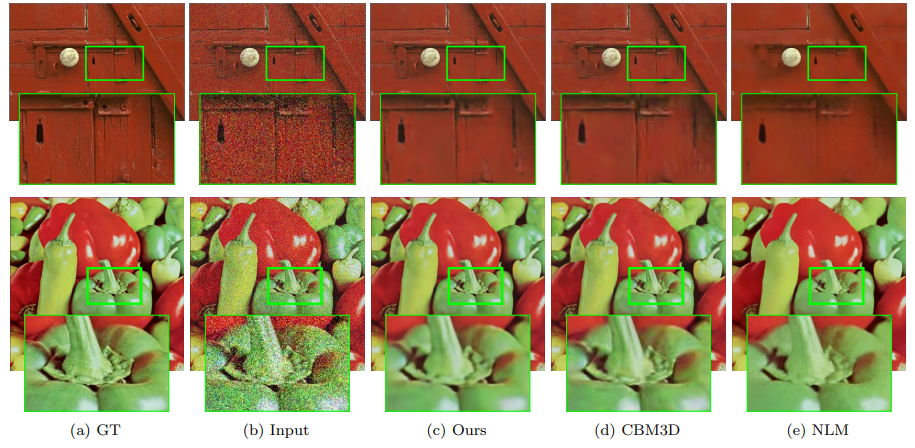
하지만 real-world에서는 이 noise가 어떠한 분포를 가지는지 알 수 없는 경우가 대부분일 것이다. 여기서 Deep Image Prior의 경우는 data driven method가 아니기 때문에 어떠한 noise분포에 한정되어있지 않고, 다양한 noise에 대해서 대응이 가능하다는 것이다.
Energy Term으로는 L2 Loss를 사용한다.
$$E(x;x') = |x-x'|^2$$
3.2 Super Resolution
Super Resolution은 기존에 Low Resolution $x_0 \in R^{3\times H \times W}$을 High Resolution $x \in R^{3 \times tH \times tW}$로 만드는 것인데, deep image prior에서는 이 문제를 inverse problem으로써 해결한다.
$$E(x; x_0) = ||d(x) - x_0||^2, \ where \ d \ is \ a \ down-sampling$$
즉, down-sampling했을 때의 이미지가 LR $x_0$와 같아지는 HR $x$를 찾는 방향으로 update가 진행된다.

위 그림에서 not-train based method인 bicubic과 비교했을 때, 더 선명한 결과를 보이고 다른 train-based method와 비교해도 quality에 전혀 손색이 없다.
3.3 Inpainting
$$E(x;x_0) = ||(x-x_0) \odot m ||^2$$
Energy Term은 L2-norm이지만 m이라는 binary mask가 포함되어 있다.
이 m은 비어있는 영역(reconstruct하고자 하는 area)에 대한 binary mask이며 즉, pixel간 비교를 통해 reconstruction을 할 때 이 영역들은 보지 않겠다는 것이다. 원래 direct하게 위 term을 적용시키면 좋지 않은 결과가 나오지만 deep image prior를 통해 implicity한 prior를 배우게 함으로써 좋은 성과를 이끌어낸다.

단순한 글자 영역 제거 외에도, 50%의 pixel을 random으로 masking하고 reconstruction한다거나 large hole에 대한 reconstruction 실험도 하였다.

large hole reconstruction problem의 경우, 저자들이 처음에는 잘 안 될 것이라고 예상했다. 왜냐면 매우 큰 area에 대한 inpainting은 semantical inpainting이기 때문에 대량의 학습 데이터를 사용하지 않는 deep image prior는 image의 context를 파악하는데 어려움이 있었을 것이라고 생각하였다.
하지만!!! 실제로는 매우 좋은 결과를 보여주었다. 즉, deep image prior가 image의 context를 이해할 수 있고, known-pixel들의 texture나 color등의 정보를 이용하여 unknown-pixel들을 잘 reconstruction한다는 것이다.
하나 주의할 점은 large hole problem의 경우, learning rate 파라메터의 값이 결과에 영향을 준다는 점이다. 위 이미지에서도 lr에 따라서 결과가 달라지는 것을 볼 수 있다.
random 50% pixels masking problem에 대해서도 잘 reconstruction하는 것을 확인할 수 있다.
3.4 Natural Pre-image
natural pre-image는 특정 layer에서의 feature representation에 대해서 어떤 정보가 loss되었고, 어떤 invariance 특성을 가지고 있는지를 시각적으로 보기 위한 task이다.
$$E(x;x_0)=||\phi (x)-\phi (x_0)||^2$$
여기서 $\phi$는 feature representation을 말하고, energy term은 해당 layer의 feature representation이 같아지는 이미지 x를 찾는 방향으로 update된다.
결과를 hand-crafted method인 TV Norm과 train-based method인 CNN model과 비교하는데,
TV Norm의 경우, weak image prior를 가지지만 상대적으로 unbiased하고,
CNN based Method의 경우, strong image prior를 가지지만 dataset에 bias한 경향을 보인다.
deep image prior는 위 두 method의 장점만 취했다고 생각하면 된다.

위 결과에서 볼 수 있듯이, TV Prior의 경우 deeper layer일수록 색상과 shape 모두 일그러지는 것을 알 수 있고, CNN-based model의 경우 색상은 얼추 비슷하지만 형태가 blur해지는 단점을 보인다.
대망의 Deep Image Prior의 경우, 정말 잘 표현해내는 것을 볼 수 있고 심지어 fc layer에서도 얼추 비슷한 shape와 color를 잘 표현한다.
3.5 Activation Maximization
$$x^*=argmax_x \phi (x)_m$$
이 task는 natural pre-image와 비슷한데, 차이점은 어떠한 특정 class에 대한 최종 layer의 노드 값이 최대화하는 방향으로 업데이트가 된다는 것이다.
더 간단히 설명하자면, 만약 내가 강아지에 대한 activation maximization을 보고 싶고 그 class가 0번이라고 하자. 최종 layer(softmax 이전)는 class개수만큼의 노드가 있을 것이고, 그 중에 0번째 노드의 value가 전체 노드들의 value들 중에서 최대값이 되는 이미지 x를 찾는 것이다.

결과에서 알 수 있듯이, TV Prior와 비교해서 더 natural한 이미지를 보여준다. 또한, 상단은 AlexNet 하단은 VGGNet을 사용하였는데 model에 따라서 결과가 달라지는 것도 알 수 있다.
3.6 Image Enhancement
이미지를 잘 드러내는 특성을 더 강조시켜주는 task라고 생각하면 된다.
구하는 과정은 denoising과 비슷한데 예제를 보면서 설명하는 것이 이해하기 쉽다.

여기서 원래 이미지가 $x_0$(상단 제일 좌측)이고, deep image prior의 update를 통해서 더 clean한 이미지 $x$(하단)가 만들어진다. 더 clean하다는 것은 feature를 더 잘 나타낸다는 것을 뜻하고, 이 이미지 $x$에서 $x_0$를 빼면 그 두드러진 특성들에 대한 pixel값($x_f$)만 남게된다. 이제 이 $x_f$를 다시 원래 이미지 $x_0$에 더해주면 특성이 강조된 이미지를 얻을 수 있다.
이 문제에서도 iteration이 너무 많이 돌게되면 원래 이미지와 똑같은 이미지를 생성하므로 early stopping이 꼭 필요하다.
3.7 Flash no-Flash
대망의 마지막 application이다....이 task는 video related problem에서 많이 사용하는, 이미지의 pair를 이용한 reconstruction으로, 제목에서 알 수 있듯이 Flash 이미지와 no-Flash 이미지 두 pair가 사용된다.

Energy Term은 denoising과 같이 L2-Norm을 사용하고, 다른 점은 input을 randomly initialized image가 아닌 flash image를 사용한다는 것이다. 즉, flash image가 guide 기능을 해준다고 생각하면 된다.
위 결과에서 deep image prior가 noise를 잘 제거하는 것을 볼 수 있으며, flash image에서 나타난 물결무늬도 다른 method와 비교해서 나타나지 않는 것이 보인다.
지금까지 Deep Image Prior 논문을 리뷰하였다. 정말 길고도 긴 여정...예제가 많다보니 길어진 것 같다.
논문을 읽고나서, 많은 데이터셋을 사용하여 학습하지 않고도 단 하나의 이미지만을 사용해서 reconsturction문제를 성공적으로 풀어낼 수 있다는 것에 많이 놀랐다. 특히 결과가 train-based method와 비교했을 때 거의 차이가 없다는 점과 image inpainting과 같은 매우 semantic한 task도 잘 동작한다는 것이 신기했다.
pair image 데이터를 모으기 어려운 reconstruction 문제에서 데이터셋 없이 좋은 성능을 낼 수 있다는 점은 정말 큰 장점이지만, 큰 문제가 아직 남아있다. 그렇다...real time으로 실행할 수 없다는 것이다. 조사한 바에 의하면, task-dependency하겠지만, 한 이미지에 대해서 reconsturction하는데 약 30분이 소요된다고 한다.....이걸 매 이미지마다 해주어야하니....답이 없다.
최근에 관련 논문들을 살펴보고 있는데, 재밌는 내용들을 찾아서 나중에 리뷰할까 한다. deep image prior처럼 1개의 noise image를 사용하는 것이 아니라, noise image와 다른 noise image간의 학습을 통해 문제를 해결하는 paper도 있고, noise image와 같은 noise image간의 학습을 하는 paper도 있다. 아직 어느정도 성능이고, 어디까지 범용성이 있는지는 알아봐야하지만 train-based이니 prediction시간에 대한 단점은 해소되지 않을까 싶다.
'논문리뷰 > Etc' 카테고리의 다른 글
| [논문 리뷰] Segment Anything Model (SAM) (3) | 2024.09.24 |
|---|---|
| [논문 리뷰] Matching Networks for one shot learning (0) | 2022.03.15 |
| [논문리뷰] Attention is All you need (0) | 2022.02.20 |
| [논문리뷰] Deep Image Prior(1) (0) | 2021.10.28 |
| [논문리뷰] SRCNN (2) | 2021.05.07 |