2021. 5. 7. 18:50ㆍ논문리뷰/Etc
오늘은 Image Super Resolution 논문을 하나 공부해보려고 한다. 이전에 접해본 적이 없는 분야라서 틀린 부분이 있거나 추가로 넣어야 하는 정보가 있다면 댓글로 써주길 바란다.
논문의 이름은 Image Super Resolution Using Deep Convolutional Networks이다.
링크: https://arxiv.org/abs/1501.00092
처음으로 딥러닝을 Super Resolution Task에 적용한 논문이고, CNN + SR의 입문서 같은 느낌이라 리뷰하게 되었다.논문을 순서대로 살펴볼 것이고, 세세하게 보려고한다.
1. Introduction

출처: commons.wikimedia.org/wiki/File:Phobos_in_super-resolution_%E2%80%93_before_and_after_image_correction_ESA204381.jpg
Single Image Super Resolution이란, Low Resolution Image(저해상도) 이미지를 High Resolution(고해상도)으로 바꾸는 Task를 말한다.
이 Task는 ill-posed problem(1)이라고 하며, 그 이유는 Low Resolution Image의 각 픽셀의 대해 unique한 해가 아닌, 다수의 해가 존재하기 때문이다.
보통 해의 범위를 사전 정보를 통해 제한함으로써 위 문제를 완화한다. 사전 정보를 학습하기 위해 state-of-art 방식은 example-based startegy를 채택한다.
- 같은 이미지의 internal similarity를 이용한다.
- 또는, external low and high-resolution exemplar pairs로부터 external 매핑 함수를 학습한다.
Internal example-based methods
이미지의 self-similarity 특성을 이용하고 이미지에서 exempler patches를 뽑아내는 방식이다.
external example-based methods
저해상도와 고해상도 pair가 데이터로 주어지고, low to high resolution으로 매핑시키는 방식이다.
어떻게 low/high resolution patches에 대하여 dictionary 또는 manifolds space를 학습시킬 것인가?
어떻게 representation schemes를 그러한 공간에서 수행할 것인가에 대해 논의한다.
출처: https://www.researchgate.net/publication/315954141_Multi-sensor_image_super-resolution_with_fuzzy_cluster_by_using_multi-scale_and_multi-view_sparse_coding_for_infrared_image
Sparse-coding-based Methods

출처: https://www.researchgate.net/publication/319707337_Performance_Evaluation_of_Super-Resolution_Methods_Using_Deep-Learning_and_Sparse-Coding_for_Improving_the_Image_Quality_of_Magnified_Images_in_Chest_Radiographs
대표적인 external-based SR Methods이다.
**자세한 내용은 다음 링크를 참고 하길바란다(https://ieeexplore.ieee.org/document/4587647)
위 방식은 다음과 같은 Sequence를 갖는다.
- input image로부터 overlapping patches들을 densely crop하고, 전처리한다.
- patches들을 low-resolution dictionary에 부호화되어 저장한다.
- high-resolution patches를 만들기위해 sparse coefficient들은 high-resolution dictionaty로 전달된다.
- 만들어진 overlapping patches들은 weighted averaging과 같은 과정을 통해 합쳐지고, 최종 output이 된다.
**위 방식은 dictionary를 최적화시키고, 학습시켜 효율적인 매핑 함수를 만드는데 집중한다.
위 파이프라인은 external example-based 방식에서 공통되게 쓰이며, 이 논문에서는 위와 같은 파이프라인이 딥러닝에서도 동일하게 적용된다는 것을 보여준다.
Super Resolution With CNN
CNN에서는 low resolution to high resolution으로 end-to-end방식의 학습을 한다.
기존의 방식과 다르게, patch공간을 모델링하기 위해서 명시적으로 manifolds나 dictionary를 학습시키지 않아도 된다.
**hidden layer를 통해 암묵적으로 얻어진다.
또한, Patch Extraction과 Aggregation(ex. weighted averaging)도 Convolution layer로 구축되며 최적화 기능을 한다. 즉, 전체 SR 파이프라인이 약간의 전후처리 외에는 모두 학습을 통해 얻어진다.
SRCNN(Super-Resolution Convolutional Neural Network)
SRCNN은 다음과 같은 특징을 가진다.
- 구조가 매우 간단하지만, the state-of-art example-based methods와 비교할 때 성능면에서 우수하다.
- CPU환경에서도 빠르게 동작한다.
- example-based methods보다 더 빠른 속도를 가진다.
- 완전히 feed-forward(2)이고, 동작 중에 optimization 과정이 필요없다.
- 크고 다양한 데이터셋이 있거나 깊은 모델을 쓰는 것이 가능할 때, 더 고품질의 복원이 가능하다.
- 하지만 그러한 데이터셋을 만드는 것은 매우 어려움.
- 3채널 color image에서 3채널에 대해 동시 처리가 가능하다.
주요성과
- SR 문제에 대해서 CNN모델을 최초로 적용.
- 전/후처리를 포함한 저해상도와 고해상도간의 end-to-end mapping.
- 기존 sparse-coding-based SR 방식과 딥러닝 기반 SR방식 간의 관계를 수립.
- 이 관계를 이용하여 네트워크 구조를 짜는데 Guidance를 줌.
- CNN이 SR문제에 대해서 좋은 성능과 속도를 가진다는 것을 증명.
2. Related Work
2.1 Image Super Resolution
Single-image super resolution은 크게 총 4가지로 분류할 수 있다.
- prediction models
- edge based methods
- image statistical methods
- patch based(or example-based) methods
이 중에 example-based 방식이 state-of-art 성능을 가진다.
이전 SR알고리즘들은 주로 gray-scale이나 single-channel이미지를 다루었다.
Color 이미지에 대해서는 YUV나 YCbCr과 같은 다른 이미지 포맷으로 변환시킨 후에, 오직 luminance(휘도)에 대해서만 SR을 적용시켰다.
2.2 CNN
CNN은 다음과 같은 장점을 가지고 있다.
- 강력한 GPU를 이용한 효율적인 훈련이 가능하다.
- Relu가 좋은 성능을 유지하면서 수렴속도를 빠르게 해준다.
- 큰 모델을 훈련시키기 위한 데이터셋 접근성이 용이하다.(ex. ImageNet)
2.3 Deep Learning for Image Restoration
이전에 딥러닝 기술을 사용한 여러 Image Restoration 연구가 있었다.
MLP를 사용하여 Image denoising, post-deblurring denoising을 하거나,
CNN을 사용하여 Image denoise, removing noisy patterns(dirt/rain)을 해결하였다.
Cui라는 사람이 internal example-based methods로 auto-encoder를 사용한 적이 있는데
그 딥러닝 모델은 연속되는 각 layer마다, auto-encoder와 self-similarity search process를
독립적으로 optimize해주어야 하기 때문에 end-to-end solution이 아니었다.
반면에 이 논문에서 제안한 SRCNN은 end-to-end 매핑으로 속도면에서 매우 빠르다.
3. CNN For Super-Resolution
본격적으로 SRCNN에 대해서 설명하는 구간이다.
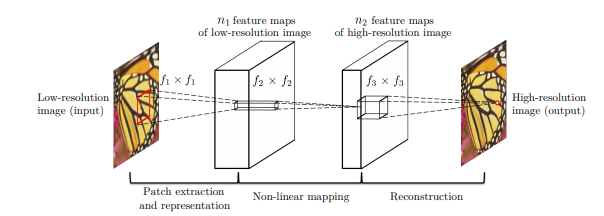
출처: https://arxiv.org/abs/1501.00092
먼저 Bicubic Interpolation을 사용하여 image를 Upscaling한다.(유일한 전처리)
**원래 이 과정 또한 Convolution layer로 나타낼 수 있지만, output size가 input size보다 크기 때문에 fractional stride라는 방식을 사용해주어야하는데 cuda-convnet과 같은 최적화 모듈을 사용하기 위해 학습에서 제외시켰다.
Y를 low resolution, F(Y)를 GT인 X와 최대한 비슷하게 변환하는 매핑함수라고 하자.
이 매핑함수 F를 학습시키는 것이 목표이며 다음과 같은 과정을 거친다.
- 1. Patch Extraction and Representation
- 저해상도 이미지 Y로부터 patches를 얻고, 각 patch를 고차원 벡터로써 표현한다.
- 벡터들은 벡터의 차원과 같은 수의 feature map들로 구성되어 있다.
- 2. Non-linear Mapping
- 고차원 벡터를 또 다른 고차원 벡터로 비선형 매핑을 한다.
- 매핑된 각 벡터들은 개념적으로 고차원의 patch를 나타낸다.
- 이 벡터들은 또 다른 feature map들의 집합으로 이루어져있다.
- 3. Reconstruction
- 위의 고해상도의 patch-wise representation들을 최종 고해상도 이미지로 만들어준다.
- 이 이미지는 GT와 비슷할 것이라고 예상된다.
3.1 Patch Extraction and Representation
Image Resotration에서 유명한 방식은 PCA, DCT, Haar등의 사전에 훈련된 기반을 이용하여 patch들을 추출하고 표현하는 것이다. 이것은 필터들을 이미지에 적용하는 것과 동일하다. 따라서 다음과 같이 나타낼 수 있다.
$$F_1(Y) = max(0, W_1 * Y + B_1)$$
여기서 $W_1$과 $B_1$은 필터 가중치와 bias를 나타내고, *은 Convolution 연산을 나타낸다.
또한, 마지막에 Relu를 사용한 것을 알 수 있다.
3.2 Non-linear mapping
첫번째 layer는 각 patch로부터 n1차원의 feature를 추출한다.
다음으로 두번째 layer는 n1차원의 벡터를 n2차원의 다른 벡터로 매핑한다.
$$F_2(Y) = max(0, W_2 * F_1(Y) + B_2)$$
1x1 필터를 사용하여 Convolution하는 것과 같으며, 3x3, 5x5필터를 사용하는 것이 Generalize하기 좋다.
비선형 매핑은 input image의 patches가 아닌 feature map의 3x3, 5x5 patches라 볼 수 있으며,
output n2차원 벡터는 개념적으로 고해상도 patches라 볼 수 있다.
Convolution layer를 더 넣을 수도 있지만, 모델 복잡도가 올라가 훈련 시간이 오래 걸리기 때문에 그렇게 하지 않았다.
3.3 Reconstruction
이전 방식에서는 예측된 high-resolution patches를 평균화하여 최종 이미지를 산출하였지만,
이 평균화(averaging) 과정은 feature map들의 집합에 적용되는, 사전에 정의된 filter로 볼 수 있다.
따라서 Convolution layer를 통해 최종 이미지를 내보낸다.
$$F(Y) = max(0, W_3 * F_2(Y) + B_3)$$
만약, high resolution patches가 다른 domain에서 표현된다면, 가중치가 먼저 coefficient를 image domain으로 project시킨 후에 평균화 하는 것을 기대하고,
high resolution patches가 Image domain에서 표현된다면 바로 필터들이 평균화 필터처럼 사용되는 것을 기대한다.
4. Relationship to sparse-coding-based methods
이번에는 Sparse-coding-based SR methods가 CNN으로 표현이 가능하다는 것을 보여준다.
Sparse-coding-based SR methods의 과정을 보여주고, 각 step마다 SRCNN과의 관계를 설명하며
왜 SRCNN이 잘 학습될 수 있는지를 설명하고 있다.
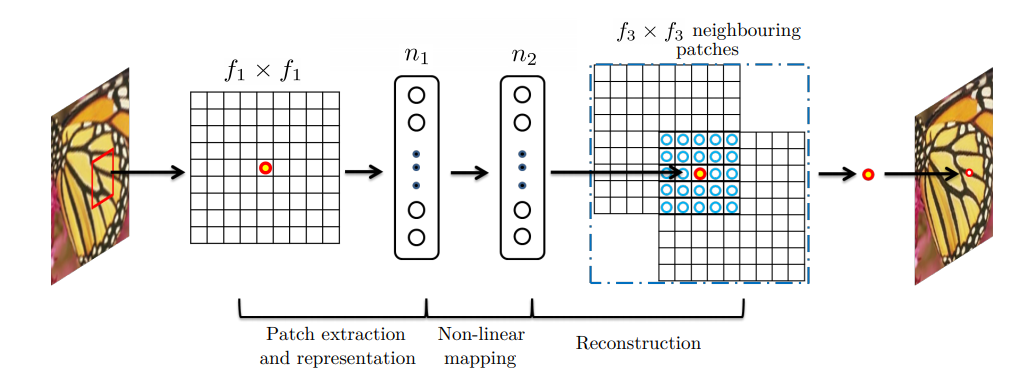
출처: https://arxiv.org/abs/1501.00092
Sparse-coding-based SR methods은 다음과 같은 과정을 거친다.
- 먼저 input에서 $f_1 x f_1$ low-resolution patch를 뽑아낸다.
- Sparse coding solver(ex. feature sign)이 patch를 low resolution dictionary로 project한다.
- 만약 dictionary size가 $n_1$이라면 $n_1$ linear filters($f_1 x f_1$)를 input_image에 적용하는 것과 같다고 볼 수 있다(mean substarction과 같은 정규화 또한 linear 연산이므로 포함됨)
- Sparse coding solver는 반복적으로 $n_1$ coefficients를 처리
- output은 $n_2$ coefficients이고, 보통 $n_1=n_2$이다.
- $n_2$coefficeints는 high-resolution patch라 할 수 있다.
- sparse coding solver는 1x1에서의 비선형 매핑 연산자라 볼 수 있다.
- 하지만 coding solver는 반복 알고리즘으로 feed-forward라 할 수 없다. 반면에 비선형 연산자는 완전한 feed-forward이며 효율적인 계산이 가능하다.
- $f_2=1$이라 하면, 비선형 연산자는 pixel-wise fully connected layer로 볼 수 있다.
- sparse coding solver는 SRCNN 내에서 첫 번째와 두 번째 layer의 역할과 같다 볼 수 있다.(relu포함)
- 따라서 SRCNN의 비선형 연산 또한 학습 과정에서 최적화가 잘 된다.
- Sparse coding 후의 $n_2$ coefficients는 high-resolution patch를 만들기 위해 high-resolution dictionary로 project된다.
- overlapping high-resolution patches들을 평균낸다.
- $n_2$ feature map에 대한 linear convolution이 같은 역할을 한다.
- (?)Reconstruction에 사용된 고차원 patch가 $f_3 x f_3$면, linear filter가 가지는 spatial support 또한 $f_3 x f_3$이다.
- filter와 patch개념 간 관계를 말하는 것 같다.
- patch가 $f_3 x f_3$이면, linear filter개념 또한 $f_3 x f_3$라는 뜻인듯?
- overlapping high-resolution patches들을 평균낸다.
따라서 sparse-coding based SR methods를 일종의 CNN이라 볼 수 있다.
SRCNN에서는 low/high resolution dictionary, 비선형 매핑, mean substraction, averaging을 모두 필터 학습으로 통합하였고, 이것은 즉 모든 연산을 포함하는 end-to-end mapping 학습이 된다.
위와 같은 분석은 하이퍼파라메터를 만들 때도 도움을 주었다.
- 마지막 layer의 필터크기를 첫 layer의 필터 크기보다 작게 주었다.
- high resolution patch의 바깥 쪽 보다는 중앙 부분에 더 집중하여 학습된다.
- 즉, 다른 주변 픽셀보다 해당 픽셀에 더 가중치를 두어 학습을 하겠다는 의미이다.
- 극한의 예)$f_3=1$이면 평균화 없이 central pixel을 그대로 사용. (1x1 convolution)
- high resolution patch의 바깥 쪽 보다는 중앙 부분에 더 집중하여 학습된다.
- $n_2 \lt n_1$, 즉 처음 hidden layer의 filter 수가 두번째 hidden layer의 filter 수보다 작게 주었다.
- 더 sparse하게 학습되기를 기대한다.
- 큰 차원에서 작은 차원으로 압축되므로 요약을 더 잘하는 것을 기대한다는 의미같다.
- 더 sparse하게 학습되기를 기대한다.
- 논문에서 best setting은 $f_1=9, f_2=1, f_3=5, n_1=64, n_2=32$라고 한다.
5. Training
Training은 모델과 데이터 전처리에 대한 내용만 간단하게 다루겠다. 더 자세한 내용을 원한다면 논문을 참고하길 바란다.
Loss Function
먼저 loss function으로는 MSE(Mean Squared Error)를 사용하고, metric은 PSNR을 사용한다.
논문에서 PSNR에서 좋은 결과가 나옴에도 불구하고 다른 metric으로도 테스트를 했으니 참고하여도 좋다.
loss 함수가 MSE가 사용되었는데 별다른 설명은 없지만 최대한 ground truth이미지와 비슷하게 변환하려는 목적인 것 같다.
(좋은 loss 함수인지는 모르겠다...ill-posed problem이라고 하면서 low-resolution pixel값이 high-resolution pixel로 mapping되는 solution이 unique하지 않은데 MSE로 하면 over-fitting이 일어나지 않을까하는 의문이 든다.)
Optimizer
Optimizer는 SGD(Stochastic Gradient Descent)를 사용하였고, 가중치를 gaussian distribution에서 random으로 initialization하였다.
또한 lr scheduler는 처음 2개 layer에 대해서는 $lr=10^{-4}$, 마지막 layer에 대해서는 $lr=10^{-5}$로 하는 것이 loss가 수렴하는데 좋다고 한다.
(어떤 방식으로 layer마다 lr을 따로 주는 것인지는 잘 모르겠다...)
Ground Truth 전처리 및 기타 사항
Ground Truth는 이미지 전체가 아닌 이미지들로부터 랜덤하게 f x f 크기로 crop된 sub image이다.
Patch가 아닌 image라는 개념을 강조하면서, patch는 겹치게 되고 평균화 같은 후처리가 필요한 반면에 sub-image는 그런 절차가 필요 없다는 것을 말하고 있다.
또한, 저해상도로 만들기 위해 Gaussian kernel로 blurring을 주고, upscaling factor로 sub-sample과 bicubic interpolation upscaling을 해준다.
Border effect를 피하기 위해 모든 convolution layer는 no padding과 input 보다 작은 차원의 output을 가지며, MSE는 X의 central pixels와 network output간의 차이만 계산한다고 한다.
**border effect: 테두리 주변에 noise가 생긱는 것.
Training Datasets
91 images와 395909 images, 즉 매우 작은 데이터셋과 매우 큰 데이터셋으로 학습했다고 한다.
데이터는 ILSVRC 2013 IMAGENET DETECTION 데이터셋을 이용하였다.
작은 데이터셋에 대해서는 sub-image의 size는 33이고 stride는 14를 주었으며,
큰 데이터셋에 대해서는 sub-image의 size는 33, strides는 33을주었다고 한다.
6. Experiments
여러 실험 결과들을 보여주고 있다. 간단하게 그래프에 대한 설명만 하고 넘어가겠다.

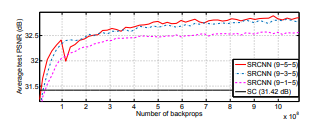
출처: https://arxiv.org/abs/1501.00092
왼쪽 사진은 데이터셋의 크기에 따른 PSNR결과를 보여주며, 데이터가 많을 수록 좋은 성능을 보인다.
오른쪽 사진은 filter size에 따른 PSNR결과를 보여주며, filter가 클 수록 좋은 성능을 보인다.

출처: https://arxiv.org/abs/1501.00092
왼쪽 사진은 trained filter들이 특정한 기능을 한다는 것을 보여주고 있다. (ex. gaussian filter, edge detector)
오른쪽 사진은 layer의 개수에 따른 PSNR 그래프를 보여주고 있다.
모델을 deep하게 만들었는데 오히려 성능이 낮아졌고, 이러한 연구가 더 필요하다는 것을 말하고 있다.
이상으로 Image Super-Resolution Using Deep Convolutional Networks에 대한 리뷰를 마치도록 하겠다.
모델의 구조를 보면 정말 간단한 것을 알 수 있다.(거의 VGGNET급...)
이런 간단한 구조에서도 어느정도 성능이 나온다는 점이 신기한 것 같고,
심지어 91개의 이미지만 가지고 훈련하였는데도 나름 괜찮은 PSNR을 보여주는 부분도 다시 한번 딥러닝의 위력을 상기시켜주는 것 같다...
나중에 시간이 되면 SRCNN 모델을 직접 구현하여 실험을 할 예정이다.
기타
(1) ill-posed Problem
ill-posed는 well-posed와 상반되는 개념이다.
well-posed problem은 다음 특성을 가진다.
- 해가 존재한다.
- 해가 unique하다. 즉, X->Y가 1:1매칭. x값 하나 당, 해 y가 하나만 존재.
- 초기 조건에 따라 해의 동작이 지속적으로 변한다. 즉, x값이 변하면 y값이 변한다.
위 조건의 상반되는 문제가 ill-posed이고, 한 x값에 대해 해 y가 여러개 존재하거나, 여러 x값에 대해 해 y가 하나만 존재하는 비정상적일 때를 말하는 것 같다.
(2) Feed-forward
feed-forward란, 단위 간의 연결이 주기를 형성하지 않는 것이다.
즉, 위 모델에선 입력 노드에서 hidden 노드를 통해 한 방향(앞)으로만 이동하며, 네트워크에 순환이나 루프가 없다는 뜻이다.
**사용된 이미지에 대해서 출처를 같이 적었지만 문제가 된다면 삭제하겠습니다. 메일로 연락주세요.
If you any problem with Images uploaded, Contact me by email please. I will delete it.
'논문리뷰 > Etc' 카테고리의 다른 글
| [논문 리뷰] Segment Anything Model (SAM) (3) | 2024.09.24 |
|---|---|
| [논문 리뷰] Matching Networks for one shot learning (0) | 2022.03.15 |
| [논문리뷰] Attention is All you need (0) | 2022.02.20 |
| [논문리뷰] Deep Image Prior(2) (6) | 2021.10.31 |
| [논문리뷰] Deep Image Prior(1) (0) | 2021.10.28 |