2021. 10. 28. 15:48ㆍ논문리뷰/Etc
이번에 소개할 논문은 Deep Image Prior라는 제목의 paper이다.
이 논문을 읽었을 때, 기존 딥러닝에 대한 고정관념이 '팍' 깨지는 느낌이 들었다. 그만큼 singular한 논문이었고, 심지어 결과도 잘 나오니 할 말이 없다....
서론은 빠르게 넘어가고, 이제 한 번 살펴보도록 하자!
쓰다보니 내용이 매우 길어져서, 두 파트로 나누어서 작성하려고 한다.
Deep Image Prior는 2017년도에 assignment된 paper이고, Image Reconstruction 분야에서 기존 딥러닝의 학습 meta를 사용하지 않고도 매우 뛰어난 성능을 보여주면서 사람들의 주목을 받았다.

1. Reconstruction Tasks
먼저 이 논문에서 등장하는 Reconstruction Task의 종류를 간단하게 살펴보자.
Denoising

Computer Vision에서 오랫동안 풀어왔던 문제 중의 하나로, 위의 사진처럼 이미지에 끼어있는(?) noise를 제거하여 clean한 이미지를 만들어내는 task이다.
Super Resolution
Denosing과 마찬가지로 고질적인 CV Task이며, Row-resolution image를 High-resolution image로 바꾸는 task이다. Ill-posed problem이기 때문에, 선명한 HR Image를 만들어내는 것은 어려운 편에 속하며, 이러한 이유로 기존 filter-based(ex. bicubic) method가 상대적으로 blur한 저품질의 결과를 보여준다.
**ill-posed problem: 하나의 input에 대응하는 output이 여러 개가 있는 문제.

위와 같은 문제에서 벗어나기 위해 대량의 데이터를 사용한 학습기반의 딥러닝 method가 사용되었고, 최근 state-of-art는 Auto-encoder, hourglass-Unet기반의 모델이 많이 사용되고 있으며, 성능 또한 filter-based 대비 out-perform하다.
Region Inpainting
어떠한 정해진 region에 대해서 reconsturct를 하는 task이다. 이건 예제로 이해하는 것이 빠르니 다음 이미지를 봐보자.
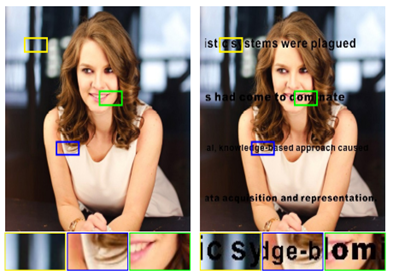
오른쪽과 같은 이미지가 있을 때, 글자가 덧씌여져 있는 것이 아주 꼴배기 싫다!! 그래서 저 글자에 대한 영역을 다 0으로 채워버렸는데...그럼 그 영역들은 하얀 공간이 되어버려 이상한건 매한가지다. 그래서 이 region(하얀 공간)을 주변 non-zero pixel들과의 상관관계를 이용하여 reconstruction해서 왼쪽과 같이 자연스러운 이미지로 만드는 것이 이 task라고 보면 된다.
2. Is Large Dataset only need for Good Model Performance?
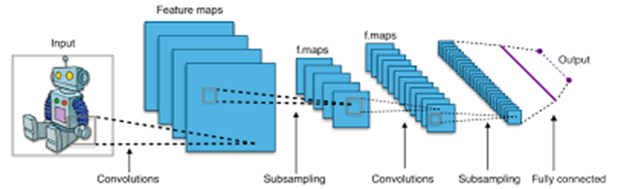
위와 같은 Reconstruction task에서 Convolution Neural Network가 이전 non-trained based method에 비해서 매우 좋은 성능을 보이고 있다는 것은 뭐 두 말하면 잔소리일 것이다.
이러한 CNN-based method는 보통 엄청나게 큰 이미지 데이터셋을 사용하여 모델을 학습을 시키는데....
그럼 CNN이 좋은 성능을 내는 이유가 이러한 큰 데이터셋으로부터 다양한 feature를 학습하였기 때문이겠네!!
라고 대부분의 사람들이 생각한다는 것이다. 물론 위 말이 완전히 틀렸다고, 이 논문에서 주장하고 있는 것은 아니다. 다만, Good Model Performance를 이야기하는데 있어서 a large dataset만으로 설명하기에는 부족함이 있다는 것이다.
Random Label Experiment
이 실험은 deep imag prior논문에서 시작한 실험은 아니고, Understanding Deep Learning Requires Rethinking Generalization이라는 논문에서 나온 것이다. 이 논문도 매우 많은 인용수를 자랑하고 있는데, 흥미가 있다면 한 번 읽어보기를 추천한다(귀찮으면 나중에 필자가 리뷰할 것이니 그 때 보아도 괜찮다).
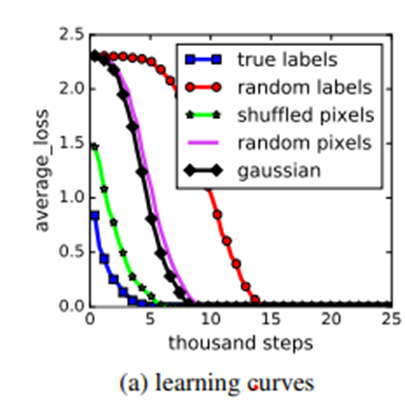
위 그림은 x-axis: number of iteration, y-axis: average loss에 대한 그래프이다. 이 실험에서는 여러 변질된 데이터셋으로 실험을 하였는데, 먼저 random labels는 기존의 true label를 shuffle하여서 image와 label간의 상관관계를 끊어버린 데이터이고, shuffled 및 random pixels는 이미지의 pixel들을 shuffle하여서 노이즈같이 만들어버린 것, gaussian은 gaussain distribution으로 gaussian noise와 같다고 보면 될 것 같다.
이 실험에서 말하고자 하는 바는, 결국 이렇게 변질된 데이터들도 엄청나게 많은 iteration을 돌리게 되면 모델에 fitting이 된다는 것이다.
즉, 만약 데이터셋이 good model performance를 정할 수 있는 매우 정확한 기준이라면 이러한 결과가 나오면 안된다.
Model Structure also has power!
위와 같은 실험을 바탕으로 이 논문에서는 Good Model Performance에는 a large dataset도 중요하지만, a good model structure가 함께 따라와야 된다라고 말한다. 심지어 datasets과 training phase가 완전히 없다고 하더라도, model architecture 자체만으로도 강한 prior를 배울 수 있는 능력(?)이 있다고 주장하면서 실제로 reconstruction task에서 위 주장이 일리가 있다는 것을 증명한다.
3. What is Prior?
논문에서 계속 prior라는 단어가 나오는데 도대체 무슨 의미를 가지는 것일까? 여기서는 논문의 저자가 좋은 설명을 해주어서 그대로 가져와봤다.

만약 사람들에게 왼쪽 그림(blurry image)을 보여주면서 이 그림을 복원해달라고 요구하면, 오른쪽과 같이 매우 detail한 이미지가 아니더라도 사람의 얼굴 형태를 어느정도 갖춘 그림을 그려낼 것이다.
그럴 수 있는 이유는 우리가, 사람들이, 어떠한 사전지식(prior)를 가지고 있어서 이를 바탕으로 얼굴의 동그란 형태와 색깔, 눈과 입의 위치등을 추정해낼 수 있다는 것이다.
4. Maximum a Posteriori(최대 사후 확률)
이제 Method를 살펴보자! 여기서는 최대 사후 확률을 사용하여 method를 설명하고 있다. 최대 사후 확률이란, 말그대로 사후 확률을 최대화 시키는 것을 말한다. 수학이 조금 나오나 어렵지 않으니 걱정하지 않아도 된다!
$$argmax_x \ p(x|x') \ = \ argmax_x \ \frac{p(x'|x)p(x)}{p(x')}$$
최대 사후 확률은 위와 같이 나타낼 수 있고, $p(x')$은 x에 대한 확률이 아니기 때문에 상수로써 배제가 되어 w같이 표현된다.
$$argmax_x \ p(x'|x)p(x)$$
즉, likelihood와 prior의 곱으로 나타낼 수 있는 것이다!
**여기서 x는 clean image, x'은 noised image라고 생각하면 이해가 더 쉬울 것이다.
What if eliminate Prior term?
만약 prior를 제거하면 어떻게 될까? 정말 prior라는 것이 중요한 역할을 하는 것일까?
위 식에서 prior부분을 제거하면 $argmax_x p(x'|x)$만이 남는 것을 알 수 있다. 이 식은 직관적으로 x에서 x'이 나오는 확률을 최대화하는 term이 되므로, 최대 나올 수 있는 결과가 x', 즉 noised image가 된다.
Change of Maximum a Posteriori
위의 최대 사후 확률 식에 negative log를 씌우면 다음과 같이 Energy Term과 Regularizer Term으로 나눌 수 있다.
$$argmax_x \ p(x'|x)p(x)$$
$$= \ argmin_x \ -logp(x'|x) -logp(x)$$
$$= \ argmin_x \ E(x;x') + R(x)$$
논문에서는 위 term들을 그대로 사용하지 않고, Parameterized를 적용시킨다.
$$argmin_{\theta} \ E(g(\theta);x') + R(g(\theta))$$
즉, 기존에는 image space(x)에서 해를 찾았다면 parameterized term에서는 $\theta$라는 다른 domain에서 해를 찾고 이를 image domain으로 mapping하게 된다.
**여기서 $g(\theta)$는 CNN architecture가 될 것이다.
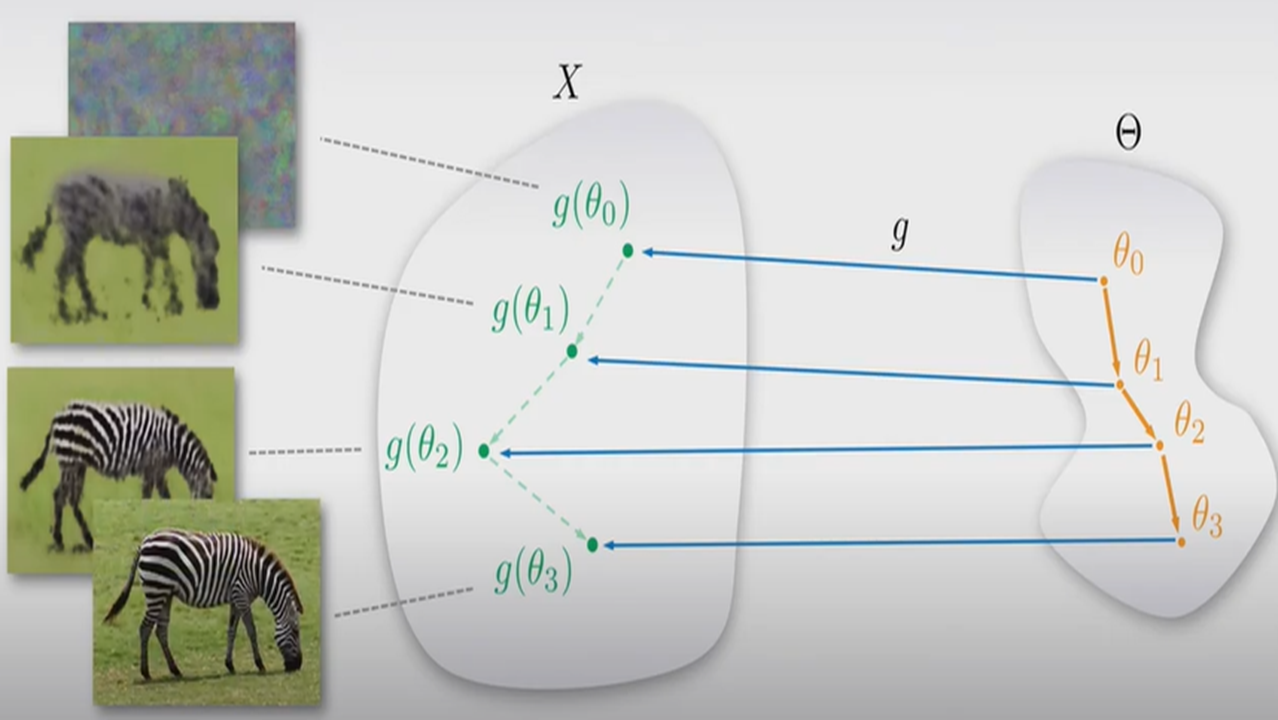
또한, Regularization Term $R(\theta)$는 task에 따라 정해져있는 Energy Term과 다르게 식으로 정의하기 매우 어렵기 때문에 제거된다. $g(\theta)$, 즉 architecture 자체가 강한 prior를 만들어낼 수 있다고 가정하기 때문에, regularization Term이 $g(\theta)$에 implicity하게 내포되어있다고 생각하여 제거를 할 수 있는 것이다.
Model Flow Chart
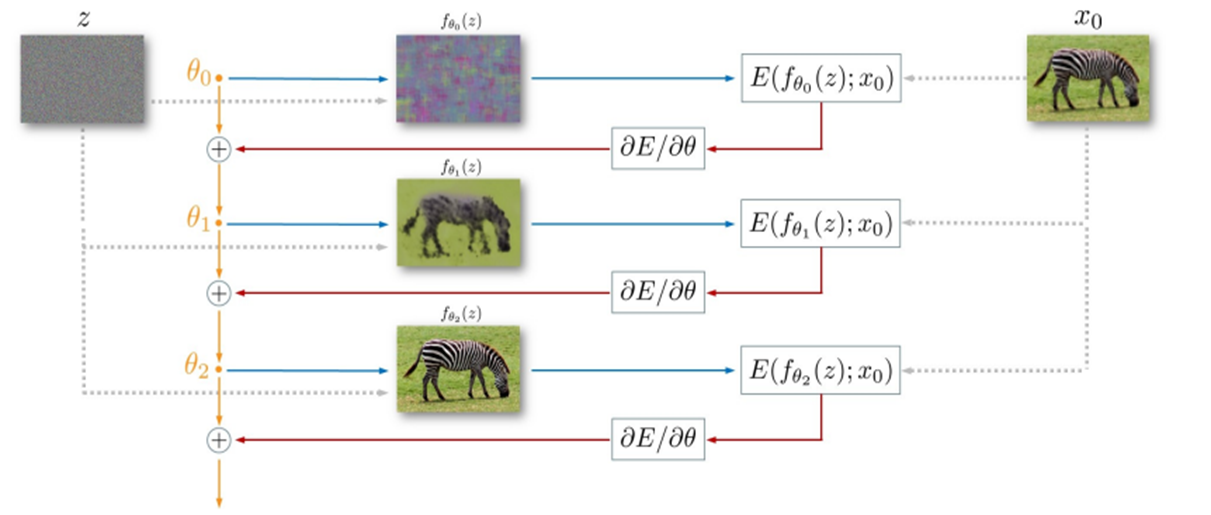
Deep Image Prior가 실제로 어떤 식으로 동작하는지 살펴보도록 하자.
- 먼저 input image z를 정하는데, 이 z는 random initialization되며 계속 고정되어있는 image이다.
- CNN Architecture에 z를 input으로 넣고, output $f_{\theta}(z)$를 얻는다.
- 이 이미지($f_{\theta}(z)$)와 $x_0$, 즉 noised image와의 loss를 구하고, gradient descent method를 통해서 $\theta$를 update시킨다.
- iteration이 끝날 때까지 2와 3번을 반복한다.
좀 더 직관적으로 설명하자면, z를 흰색 도화지라고 생각하고 얼룩말을 그리게 하는 것이다. 처음은 prior를 배우지 못했으므로 이상한 그림이 나올 것이고, prior를 배울 수록 정확한 얼룩말 이미지를 그릴 수 있을 것이다.
근데 여기서 하나 의문이 들 수 있다. prior를 배우는 것까진 알겠는데 왜 denosing이나 super resolution같은 더 고품질의 이미지를 만들 수 있는거지???
이 의문을 해소시켜주기 위해 논문에서는 다음과 같은 설명을 한다.....
be continue in next post.....

최대한 자세하게 설명하려고 하다보니 글이 매우 길어져서 다음 post에서 이어하도록 하겠다. ㅎㅎ..
reference
1. deep image prior paper: https://arxiv.org/abs/1711.10925
Deep Image Prior
Deep convolutional networks have become a popular tool for image generation and restoration. Generally, their excellent performance is imputed to their ability to learn realistic image priors from a large number of example images. In this paper, we show th
arxiv.org
2. understanding deep learning requires rethinking generalization: https://arxiv.org/abs/1611.03530
Understanding deep learning requires rethinking generalization
Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or t
arxiv.org
3. deep image prior presentation by writer: https://www.youtube.com/watch?v=-g1NsTuP1_I
'논문리뷰 > Etc' 카테고리의 다른 글
| [논문 리뷰] Segment Anything Model (SAM) (3) | 2024.09.24 |
|---|---|
| [논문 리뷰] Matching Networks for one shot learning (0) | 2022.03.15 |
| [논문리뷰] Attention is All you need (0) | 2022.02.20 |
| [논문리뷰] Deep Image Prior(2) (6) | 2021.10.31 |
| [논문리뷰] SRCNN (2) | 2021.05.07 |