2025. 3. 28. 14:09ㆍ논문리뷰/Diffusion
최근까지 진행하던 연구가 마무리되면서, 새로운 주제를 탐색하던 중 "Diffusion"에 큰 관심이 생겼다. 현재는 Diffusion의 근본 논문들을 공부하고 있는데, 수학적인 내용이 많아 정리가 필요한 부분도 있다. 이 부분은 나중에 기회가 되면 따로 글로 정리해볼 생각이다.
이번에 소개할 논문은 ICLR 2024에서 Oral 발표로 선정된 "An Efficient Architecture for Large-scale Text-to-image Diffusion Models"이고, 소제목으로 ‘Würstchen’이라는 이름이 붙어 있다. 제목에서 알 수 있듯이, 이 논문은 Text-to-image Diffusion 모델을 어떻게 하면 더 효율적인 아키텍처로 만들 수 있을까에 대해 다루고 있다.
https://arxiv.org/abs/2306.00637
Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models
We introduce Würstchen, a novel architecture for text-to-image synthesis that combines competitive performance with unprecedented cost-effectiveness for large-scale text-to-image diffusion models. A key contribution of our work is to develop a latent diff
arxiv.org
먼저 처음 든 생각은 도대체 저 소제목이 무엇을 뜻하는가 였다. 단순 영어가 아니인지라 구글링을 해보았는데...

오잉? ㅋㅋㅋ 소시지가 나와서 살짝 당황했다...그리고 논문을 읽는 동안 이 소시지를 소제목으로 정한 의도를 파악하려고 노력하였는데...결론은 실패...혹시 이 글을 읽고 그 의도를 파악하였다면 댓글로 알려주면 감사하겠다...
1. Text-to-image Generation
먼저 text-to-image generation이란 task가 무엇인지 가볍게 살펴보자.
어떤 prompt를 조건으로 주고, 이를 바탕으로 생성기를 통해 이미지를 만들어내는 과정을 text-to-image generation이라고 한다. 이때 prompt는 이미지에 대한 설명 문장이며, 그 형식(e.g. caption, instruction 등)을 어떻게 구성하느냐 역시 최근 활발히 연구되고 있는 주제 중 하나다.
또한, 여기서 Generator는 Diffusion 모델뿐 아니라, 과거 생성 모델의 SOTA였던 GAN, VAE, Flow-based model 등도 모두 포함하는 개념이다.
2. Diffusion
Diffusion은 최근 몇 년 사이에 다양한 생성(generative) 작업에서 주로 사용되는 프레임워크로 자리 잡았다. 우수한 성능과 함께, GAN보다 안정적인 학습 과정을 제공한다는 점에서 큰 장점을 가진다. 이 글에서는 Diffusion의 기본적인 학습 및 샘플링 과정만 간단히 다루고, 보다 디테일한 내용은 추후에 따로 리뷰할 예정이다
Training
먼저 Forward Diffusion Process를 살펴보자. 어떤 입력 이미지가 주어졌을 때, 정해진 time-step 수에 걸쳐 노이즈
다음은 Reverse Denoising Process로, 실제로 모델 학습이 이루어지는 부분이다. 위에서 생성된 가우시안 노이즈로부터 시작해 점진적으로 노이즈를 제거하면서 원래의 입력 이미지를 복원하는 것이 목표다. 이 과정을 조금 더 자세히 살펴보면, 특정 time-step
단, 이 과정은 순차적(T-> T-1 ->-> 0)으로 이루어지진 않는다. 학습 시에는 0부터 T사이의 time-steps 중 하나를 uniform하게 랜덤 샘플링 한 뒤, 해당 시점 … 에서의 noisy 이미지에 대한 loss를 계산하고 역전파를 수행하는 방식으로 학습이 진행된다. t
Sampling
이 과정에서는 가우시안 노이즈 (time-step T)를 입력으로 받아 학습된 UNet 모델을 통해 점차 denoising을 수행하며 이미지를 생성해나간다. 이 때는 T부터 0까지 순차적으로 time-step을 거친다.
3. Computationally Demanding
Diffusion 모델의 고질적인 문제 중 하나는, denoising 단계를 여러 번 반복해야 한다는 점이다. 그만큼 UNet 모델도 반복적으로 호출되어야 하며, 이는 계산 복잡도를 급격히 증가시키는 원인이 된다. 단순하게 생각해보면, 샘플링 과정에서 GAN은 UNet을 한 번만 통과하지만, Diffusion 모델은 적게는 50번, 많게는 1000번까지 반복된다 (일반적으로 time-step 수가 많을수록 이미지 품질은 좋아진다). 그만큼 연산량도 GAN 대비 수십 배 이상 커질 수밖에 없다.
예를 들어, 기존 DDPM(Denoising Diffusion Probabilistic Model)보다 연산 효율을 크게 개선한 Stable Diffusion조차도, 1.4 버전 기준으로 A100 GPU 1대에서 학습하는 데 약 150,000시간이 걸린다고 알려져 있다.
간단히 계산해보면
150,000시간 = 6,250일 = 약 208개월 = 무려 17년... 😅
진짜 웬만한 인내심 아니면 감당이 안 되는 수준이다.
4. Previous Researches
Stable Diffusion
앞서 언급한 Stable Diffusion을 간단히 설명하자면 다음과 같다.
기존 DDPM은 forward와 reverse 과정을 모두 pixel space에서 진행하기 때문에, 매우 고차원의 데이터를 직접 처리해야 한다는 단점이 있다. 이로 인해 연산량이 매우 크고 비효율적이다.
Stable Diffusion은 이러한 문제를 해결하기 위해, 입력 데이터를 저차원 표현(latent representation)으로 한 번 임베딩한 후, 그 latent space 상에서 forward와 reverse diffusion을 진행하자는 아이디어에서 출발했다. 즉, pixel space → latent space로 옮겨 연산 효율을 극대화하는 것이 목적이다.
이 방법은 연산량을 크게 줄여준다는 장점이 있지만, 한 가지 제한점도 존재한다. 바로, latent space로 변환할 때 사용하는 pre-trained encoder-decoder 모델(주로 VQGAN이나 CLIP)이 입력 이미지의 정보를 얼마나 잘 보존하면서 압축하느냐에 따라 전체 성능이 영향을 받는다는 점이다.
Imagen
또 다른 접근 방식으로는, pixel space에서 diffusion 학습을 진행하되 저해상도 이미지를 사용하고, 이후 후처리 단계에서 고해상도를 복원하는 방법이 있다. 대표적인 예시가 바로 Imagen으로, 먼저 저해상도 이미지를 생성한 뒤, 이를 super-resolution diffusion 모델에 통과시켜 최종적으로 고해상도 이미지를 생성하는 구조를 가지고 있다.
이런 관점에서 보면, Würstchen은 Stable Diffusion과 Imagen의 장점을 잘 조합한 프레임워크라고도 볼 수 있다.
5. Würstchen
이제 논문에서 제안하는 방법론에 대해서 다루어 보자. Würstchen 은 전체 학습 과정과 추론 과정을 3가지의 stage로 나누어서 진행한다.
Training

순차적으로 살펴보면,

Stage A에서는 VQGAN을 활용해 입력 이미지를 복원하는 방식의 학습이 진행된다. 이 과정을 통해 모델은 고해상도 이미지의 중요한 시각적 정보를 압축된 형태로 표현할 수 있도록 훈련된다. 학습이 완료되면, 예를 들어
What is VQGAN?
VQGAN에 대해서 설명하기 전에 먼저 VQ-VAE를 살펴보자.

기존의 VAE(Variational Autoencoder)는 인코더에서 latent vector를 생성할 때, continuous한 gaussian 분포로부터 샘플링을 수행한다. 하지만 이런 방식은 샘플링 과정이 너무 거칠고 불확실성이 크다 보니, 결국 디코더 쪽에 학습 부담이 과도하게 집중되는 문제가 발생할 수 있다.
이에 비해 VQ-VAE는 latent vector를 continuous한 공간에서 추정하는 대신, codebook을 통한 categorical 분포를 기반으로 추정하도록 설계되었다.
그 과정은 다음과 같다:
- 먼저 CNN을 통해 입력 이미지
X Ze(X) - 그 후 이
Ze(X) - 가장 가까운 원소의 index를 선택하고, 이를 통해 확률 분포
q(z|x) - 선택된 index에 해당하는 code들을 모아 vector-quantized representation
Zq(x) - 마지막으로, 이
Zq(x)
이러한 방식은 latent space의 구조를 보다 정돈되고 해석 가능하게 만들고, 동시에 디코더에 과도한 학습 부담이 가지 않도록 해주는 효과를 낸다.
여기서 codebook 또한 learnable parameters이다.

VQGAN은 쉽게 말해, VQ-VAE를 GAN 구조로 확장한 버전이라고 이해할 수 있다. 기존의 VQ-VAE 구조에 더해, 각 이미지 patch가 실제(real)인지 생성된(fake) 것인지를 구분하는 discriminator가 도입되었고, 또한 codebook을 학습한 이후, 그 코드를 바탕으로 Vision Transformer를 활용한 auto-regressive 이미지 생성 단계가 추가되었다.
하지만 Würstchen에서는 VQGAN의 인코더만을 활용하기 때문에, Transformer를 이용한 생성 과정에 대한 깊은 이해는 굳이 필요하지 않다. 핵심은, 이미지를 latent token으로 압축해주는 인코더의 역할이 Stage A에서 사용된다는 점이다.

Stage B에서는, 앞선 Stage A에서 VQGAN 인코더를 통해 얻은 latent token을 입력으로 사용한다. 이 latent 입력을 바탕으로 diffusion 학습을 수행하는 모델이 바로
- 먼저, 원본 이미지(
1024×1024 786×786 - 그리고 나서 이 이미지는 SC를 통해 feature vector로 변환된다. 이름은 거창하지만, 실제로는 잘 알려진 CNN 기반 모델 (학습된 EfficientNetV2) 을 활용하며, 학습 과정 중에 SC에 대한 fine-tuning이 함께 진행된다.
또한, 몇 가지 추가적인 기법들도 적용된다:
- SC의 출력에 노이즈를 섞어주는 것 — 실제 샘플링 과정에서는 입력 자체가 노이즈 상태이기 때문에, condition도 노이즈 상황을 반영해주는 것이 합리적이다.
- SC condition(
CSC
Classifier-free guidance는 간단히 설명하면, unconditional loss와 conditional loss를 선형 보간(linear interpolation) 하여, 모델이 조건을 어느 정도 반영할지를 조절하는 기법이다. 보통 수식은 uncond + w * (cond - uncond) 형태로 쓰이며, Wuerstchen에서는 조건으로 SC와 텍스트 embedding(text-conditioning) 두 가지가 함께 들어온다. 이 중 SC 부분의 guidance를 확률적으로 drop하여, 생성 과정에 더 다양한 샘플링 가능성을 열어주는 방식이다.

Stage C에서는, Stage B의 학습이 완료된 후, 해당 단계에서 사용된 Semantic Compressor(SC)의 출력을 입력 조건으로 삼아 한 번 더 diffusion 학습을 수행한다. 이 단계에서는 이미 latent vector의 차원이 충분히 낮아진 상태이기 때문에, 별도의 downsampling 없는 총 16개의 ConvNeXt 블록으로 구성된Diffusion 모델이 사용된다.
오른쪽에 등장하는 수식은, 모델의 파라미터가 초기에 0을 예측하도록 초기화된 경우, 특히 노이즈가 많은 초기 time-step 구간에서 예측 오차가 과도하게 커질 수 있는 문제를 보완하기 위한 것이다. 이에 따라 noise prediction 식 자체를 약간 수정하여 안정성을 확보한다.
또한 이 단계에서도, text-conditioning을 랜덤으로 drop하는 기법이 적용된다. 이러한 dropout은 모델이 조건 없이도 유의미한 이미지를 생성할 수 있도록 도와주고, 샘플 다양성을 확보하는 데 기여한다.
Inference

추론 과정(Inference)은 구조적으로 학습 과정의 반대 방향을 그대로 따라간다.
가장 먼저, 가우시안 노이즈로부터 시작하여 Stage C의 diffusion 모델이
Stage B에서는 가우시안 노이즈를 입력으로 Stage C에서 출력된 condition과 함께 더 큰 크기인
마지막으로, 이 latent vector는 Stage A에서 학습한 VQGAN의 디코더에 입력되어, 최종적으로
6. Experiments and Evaluation
Automated Text-to-image Evaluation


모델 성능 평가는 PickScore라는 지표를 사용한다. 이 지표는 2024년 NeurIPS에 발표된 논문에서 제안된 것으로, 사람의 선호도를 흉내 내도록 학습된 평가 지표다. 즉, 생성된 이미지들을 비교할 때 실제로 사람들이 어떤 이미지를 더 좋아할지를 예측하는 방식으로 점수를 매긴다.
위 지표에서 퍼센티지가 높을 수록 Würstchen의 선호도가 높은 것이라고 보면 되는데, 비슷한 리소스를 사용한 다른 모델들(Baseline LDM, DF-GAN, GALIP)보다 매우 높은 선호도를 기록했고, 더 많은 연산 리소스를 투입한 Stable Diffusion 계열 모델들보다도 오히려 더 높은 점수를 보였다.
다만, SD XL에게는 PickScore에서 밀렸는데, 이 모델은 capacity가 크고, 사용된 학습 데이터나 연산량이 공개되어 있지 않기 때문에 논문에서는 공정한 비교 대상에서 제외한다고 덧붙인다.
Baseline LDM은 Wurstchen과 연산량만 똑같아지도록 조정한 stable diffusion이라고 생각하면 된다.
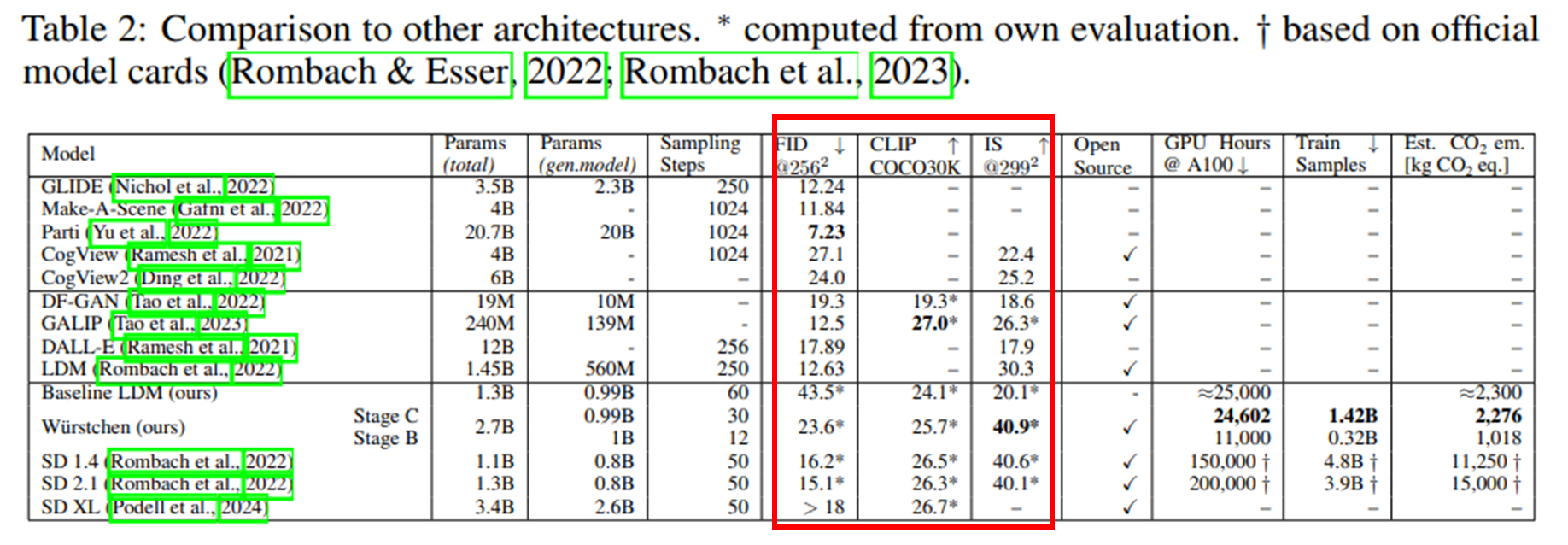
그 외의 평가 지표들도 함께 살펴보면, Inception Score(IS)는 가장 높은 점수를 기록했지만, 반면 FID(Frechet Inception Distance)는 다소 SOTA 모델들에 비해 낮은 성능을 보였다. 논문에서는 이 이유에 대해, Würstchen이 상대적으로 더 부드러운(smooth)이미지를 생성하려는 경향이 있어, FID 기준에서 불리하게 작용했을 가능성이 있다고 설명한다. 즉, 시각적으로는 더 자연스럽고 깨끗하지만, 통계적으로는 기존 데이터와의 분포 차이가 더 커질 수 있다는 이야기다.
Human Preference Evaluation

실제 사람들로부터 평가된 지표에 대해서 보여주고 있다. 처음에는 user identity를 고려하지 않고, 단순히 총 선호 개수를 기준으로 결과를 집계했는데, 이 경우 COCO 데이터셋에서는 성능 향상이 뚜렷하게 나타나지 않았다. 논문에서는 그 이유로 "프롬프트가 애매한 경우, 생성된 이미지가 다양해지고 이로 인해 선호도 판단이 개인적인 취향에 더 크게 좌우되는 경향이 생긴다."고 설명한다. 이러한 특성 때문에, 더 많은 비교를 수행한 사용자들((c), (d)에서 왼쪽 그룹)에 결과가 편향되는 문제가 발생하게 된다.
이를 보완하기 위해, 최종 결과에서는 상위 50번째 percentile 이상의 사용자들만 포함하여 집계했고, 이 기준에서는 두 데이터셋 모두에서 일관되게 좋은 성능을 보여주었다 ((b) 참고).
Efficiency

이 논문의 핵심은 "효율적인 diffusion 모델을 만들자"이기 때문에, 실제 연산 효율이 어떻게 나오는지가 굉장히 중요한 포인트다. 논문에서 제시한 표를 보면, 전체 파라미터 수에서는 기존 모델들과 큰 차이가 없지만 샘플링에 필요한 step 수는 크게 줄었고, 실제 학습에 걸리는 GPU 시간 역시 현저히 적게 나온 것을 확인할 수 있다(그런데 그 수치조차 계산해보면… 3년...ㅋㅋ).
참고로, 표에는 Stage A에 대한 GPU 시간이 빠져 있는데, 그 이유는 명시되어 있지 않다. 다만 추정하기로는 학습된 VQGAN을 단순히 fine-tuning하는 작업은 시간이 매우 적게 걸리기 때문에 측정 대상에서 제외한 것으로 보인다.
Results

결과는 모든 diffusion 모델이 그렇듯이 잘 나온다.
Ablation Study
또 하나 supplementary material에 재밌는 실험이 있어서 가져와보았는데,

직접적으로 의도하지 않았음에도 불구하고 Stage C가 이미지 생성기 역할을 담당하고, Stage B가 Super resolution 역할을 한다는 것을 visualization으로 보여준다.