2022. 9. 6. 23:47ㆍ인공지능/딥러닝 모델
You Only Look Once: Unified, Real-Time Object Detection
Object detection task에서 좋은 성능을 보였던 RCNN 계열은 성능은 좋지만 end-to-end 학습이 안되고 stage에 따라 학습을 여러 번 해야하는 번거로움이 있었다. 또한, region proposal과 같은 방법은 window 마다 모델을 통과시켜야 하였기 때문에 속도 측면에서 매우 큰 단점을 가졌다.
YOLO는 위와 같은 단점을 해결하고자 문제를 regression task로 바꾸어 하나의 모델로 end-to-end 학습을 할 수 있도록 만든 방법이다.
https://arxiv.org/abs/1506.02640
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
0. Preliminary
0.1 Localization과 Classification
- classification :입력 이미지에 대해 사전에 입력된 어떠한 label로 분류해내는것.
- localization : 분류함과 동시에 분류된 객체가 이미지 어디에 위치해있는지도 알아내는 것.
- Detection : 한 이미지에 여러 객체가 있는 경우에 classification과 localization을 수행하는 것.

기존 CNN을 이용한 classification에서는 Softmax를 이용해 class를 분류.
- classification with localization
- softmax에 bounding box에 대한 coordinate를 output에 추가.
target label y는 위와 같이 정의한다.
Pc bx,y,w,h C1,2,3 - 만약 object가 존재하지 않는다면
(Pc=0)
0.2 Sliding WIndow
sliding window란, 위와 같이 여러 크기의 window filter(위 이미지에서 빨간색 사각형 부분)를 image의 위 왼쪽 끝에서부터 아래 오른쪽 끝까지 훑으면서 각 window filter 내에 들어간 영역 대해 차례대로 convolution network를 통해 object인지 아닌지를 분류하는 것을 말한다.
단점
- window filter로 전체 이미지를 훑으면서 모든 각 영역(window filter 내에 들어간 부분)에 대해서 개별적으로 convolution을 시행하기 때문에 computational cost가 매우 많이 든다.
- stride를 높게 준다면 훑는 region의 수는 줄어들지만, 모양이 거칠어지기 때문에 결과에 영향을 줄 수 있다.
- localization을 하기가 거의 불가능하다.
- stride를 낮게 주면 smooth한 모양을 얻을 수 있지만, 수많은 영역에 대해 각각 convolution net을 시행해야하므로 computational cost가 매우 높다.
- 매우 느리다.
0.3 Convolutional implementation of sliding window
어떻게 Fully Connceted layer를 convolutions layer로 바꿀 수 있을까?
- 마지막 output의 각 셀이 각 region을 conv net한 결과와 대치됨.
- 예를들어 2x2x4 output의 첫번째 셀(빨간색 동그라미)은 16x16x3 이미지에서 첫번째 필터(빨간색 사각형 부분)를 conv net한 것과 대치.
- 이렇게 FC layer를 convolution layer로 나타냄으로써 각 영역에 대해서 conv net을 실행시키는 것이 아닌 전체 이미지에 대해서 window filter를 적용시켜 sliding window 효과를 낼 수 있게 되었다.
- 위에서 stride=2
1. YOLO(You Only Look Once)
- R-CNN은 복잡한 처리과정으로 인해 Object의 디테일을 한 눈에 파악하기가 어렵다.
- YOLO는 이미지 내의 bounding box 와 class probability를 single regression problem으로 간주해, 이미지를 한 번 보는 것으로 object의 종류와 위치를 추측한다.
장점
- 간단한 처리과정으로 속도가 매우 빠르다.
- image 전체를 한 번에 바라보는 방식으로 class에 대한 맥락적 이해도가 높다.
- 낮은 background 에러
- Object에 대해 좀 더 일반화된 특징을 학습.
- 예를 들어, natural image로 학습을 한 뒤, 이를 art image에 대해 test하면 상대적으로 높은 성능을 보여준다.
- single neural network forward 만으로 결과를 얻을 수 있어 매우 빠르다.
- single convolution network는 물체의 bounding box와 bounding box안의 object가 무엇인지 동시에 예측.
단점
- 상대적으로 낮은 정확도. *특히 작은 object.
1.1 Simple YOLO Algorithm
- SxS Grid로 input image를 나눈다. (위 이미지에서는 3x3)
- training 시, 각 Grid에 대해서 8차원의 label이 주어진다.
Pc bx,y,w,h c1,2,3
- 3x3 그리드 셀에 label이 8차원이므로 target output은 3x3x8.
- 각 객체에 대한 중심점을 포함하고 있는 grid에 대해서만 객체가 그 grid내에 있다고 인식.
- 예를 들어, 위 이미지에서 정가운데 grid는 각 객체의 조그마한 부분들을 포함하고 있지만 중심점은 포함하지 않으므로 위 label에서
Pc=0 - 단, 각 그리드 셀에 하나 이상의 객체가 없을 경우에만 위 알고리즘이 잘 작동.
- 따라서 보통 grid를 19x19 또는 그 이상의 큰 grid를 주어 한 grid cell안에 여러 객체의 중심점이 들어가있을 경우를 줄인다.
- 바운딩 볼이 명시적으로 좌표를 출력하기 때문에 모든 형상비의 bounding box를 출력할 수 있을 뿐만 아니라, 슬라이딩 윈도우 분류기의 stride 크기에 의해 결정되지 않는 훨씬 정확한 좌표를 출력 할 수 있다.
- 각 grid 별로 conv net을 실행하는하는 것이 아니라 한 단위의 convolution으로 실행하기 때문에 매우 빠르다.
1.2 Unified Detection
- component들을 single convolution network에 통합.
- 이미지로부터 bounding box와 class들을 동시에 detect.
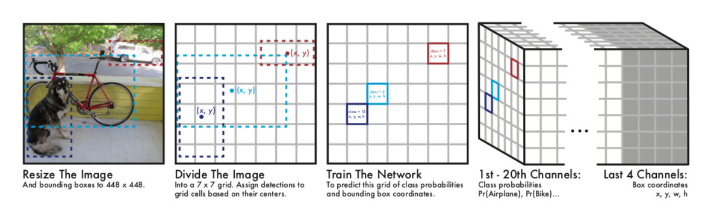
7x7 Grid: 이미지를 7x7로 나누고, 해당 Object의 중심점이 위치한 grid에서 해당 물체의 bounding box와 class를 출력한다.

- input image를 S X S grid로 나눈다.
- 각각의 grid cell은 B개의 bounding box와 각 bounding box에 대한 confidence score를 갖는다.
- 만약 cell에 object가 존재하지 않는다면 confidence score는 0.
- Confidence Score :
Pr(Object)∗IOUtruthpred - 즉, 해당 모델이 해당 box안에 object가 있을 확률이 얼마나 되는지, 그리고 그 box가 얼마나 정확한지.
- 각각의 grid cell은 C개의 conditional class probability를 갖는다.
- Conditional Class Probability:
Pr(Classi|Object) - 하나의 grid cell은 예측된 상자 수 B와는 관계없이 한가지 종류의 Class에 대한 확률만 계산한다.
- Conditional Class Probability:
- 각각의 bounding box는 x, y, w, h, confidence로 구성된다.
- (x, y) : Bounding Box의 중심점. grid cell의 범위에 대한 상대값이 입력된다.
- (w, h) : 전체 이미지의 width, height에 대한 상대값이 입력된다.
- 예) 만약 x가 grid cell의 가장 왼쪽에 있다면 x=0, y가 grid cell의 중간에 있다면 y=0.5.
- 예) bbox의 width가 이미지 width의 절반이라면 w=0.5.
- Test time에는 conditional class probability와 bounding box의 confidence score를 곱하여 class-specific confidence score를 얻는다.
1.3 Network Design
- GoogLeNet for image classification 모델을 기반으로 함.
- 9개의 convolutional layer와 2개의 fully connected layers
- 448x448 이미지의 해상도가 점점 작아져서 7x7까지 해상도가 줄어드는데 이것을 FC 2번을 통해 4096x1, 1470x1 형태가 되고 Reshape 을 통해 다시 7x7 해상도로 복원한다.
- FC 과정으로 인해 7x7 의 모든 셀의 receptive field 는 영상 전체가 된다.
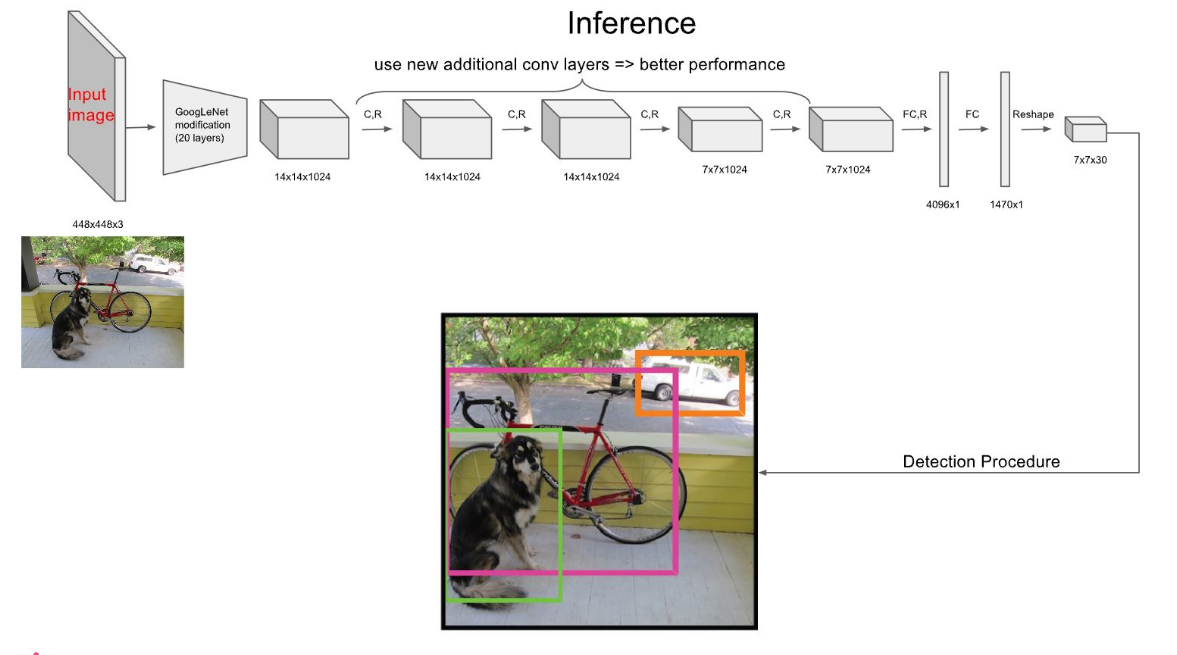
1.4 Inference Process
7x7은 49개의 Grid Cell을 의미한다.
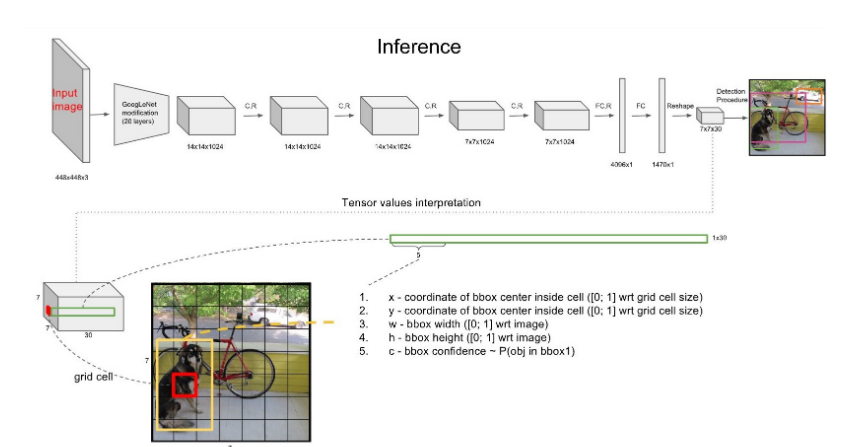
각각의 Grid Cell은 B개의 bounding box를 가지고 있는데(여기선 B=2), 앞 5개의 값은 해당 Grid cell의 첫 번째 bounding box에 대한 값이 채워져있다.
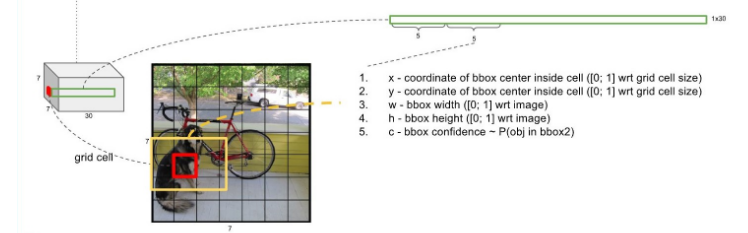
그 다음 5개의 값은 두 번째 bounding box에 대한 내용이다.
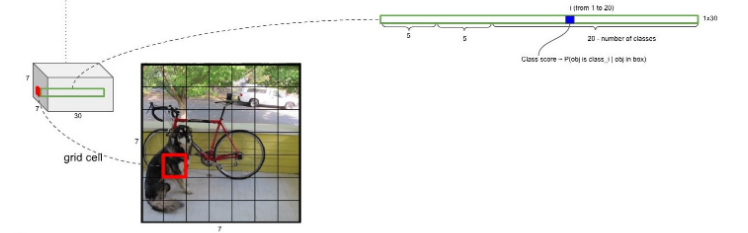
- 나머지 20개의 값은 20개의 class에 대한 conditional class probability에 해당한다.
- 즉, object가 있다면 그것이 어떤 클래스일지에 대한 확률
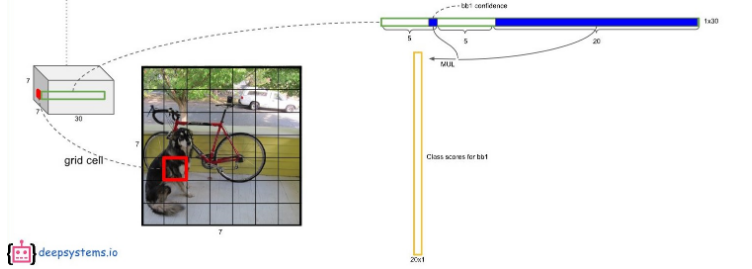
- 첫번째 bounding box의 confidence score와 각 conditional class probability를 곱하면 첫 번째 bounding box의 class specific confidence score가 나온다.
- 마찬가지로, 두 번째 bounding box의 confidence score와 각 conditional class probability를 곱하면 두번째 bounding box의 class specific confidence score가 나온다.
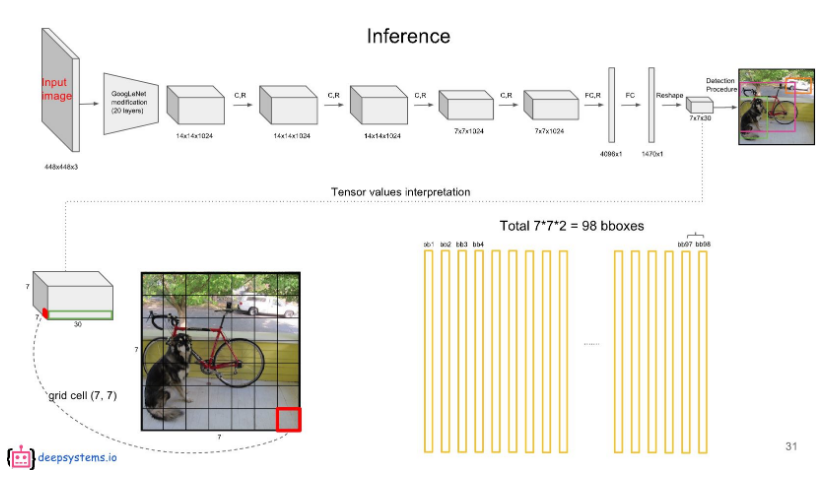
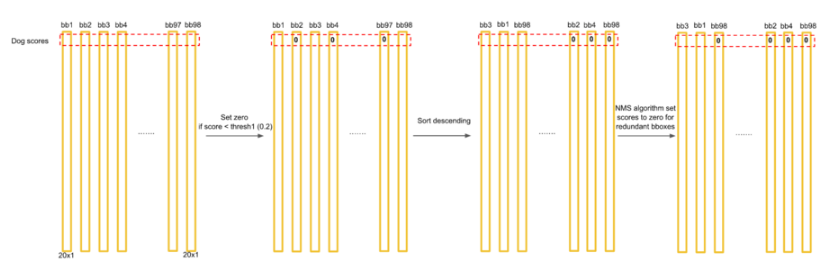
- 이 계산을 각 bounding box에 대해 하게되면 총 98(7x7x2)개의 class specific confidence score를 얻을 수 있다.
- 이 98개의 class specific confidence score에 대해 먼저 정한 threshold보다 낮은 것은 전부 0으로 채워준다.
- 그 다음 class specific confidence score 크기 순으로 정렬을 한다.
- 남은 bbox에 대해 20개의 클래스를 기준으로 각 클래스마다 독립적으로 non-maximum suppression을 하여, object에 대한 class 및 bounding box location을 결정한다.
1.5 Training Process
전제 조건
- Grid cell의 여러 bounding box들 중, ground-truth box와의 IOU가 가장 높은 bounding box를 predictor로 설정.
- 1의 기준에 따라 아래 기호들이 사용된다.
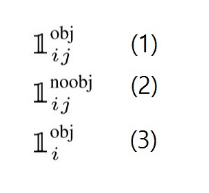
(1): Object가 존재하는 grid cell i의 predictor bounding box j.
(2): Object가 존재하지 않는 gird cell i의 bounding box j
(3): Object가 존재하는 grid cell i
* Ground-truth box의 중심점이 어떤 grid cell 내부에 위치하면, 그 grid cell에는 Object가 존재한다고 여긴다.
Loss Function

(1): Object가 존재하는 grid cell i의 predictor bounding box j에 대해, x와 y의 loss를 계산.
(2): Object가 존재하는 grid cell i의 predictor bounding box j에 대해, w와 h의 loss를 계산. 큰 box에 대해서는 small derivation을 반영하기 위해 제곱근을 취한 후, sum-squared error를 한다. ( 같은 error라도 larger box의 경우 상대적으로 IOU에 영향을 적게 준다.)
(3): Object가 존재하는 gird cell i의 predictor bounding box j에 대해, confidence score의 loss를 계산.
(4): Object가 존재하지 않는 grid cell i의 bounding box j에 대해, confidence score의 loss를 계산.
(5): Object가 존재하는 grid cell i에 대해, conditional class probability의 loss계산.
1.6 YOLO의 한계
- 각각의 grid cell이 하나의 클래스만을 예측할 수 있으므로, 작은 object가 어려개 다다닥 붙어있으면 예측이 제대로 이루어지지 못한다.
- bounding box의 형태가 training data를 통해서만 학습되므로, 새로운/독특한 형태의 bounding box의 경우 정확히 예측하지 못한다.
- 몇 단계의 layer를 거쳐서 나온 feature map을 대상으로 bounding box를 예측하므로 localization이 다소 부정확해지는 경우가 있다.
2. Improve YOLO
2.1 how to encode label vector
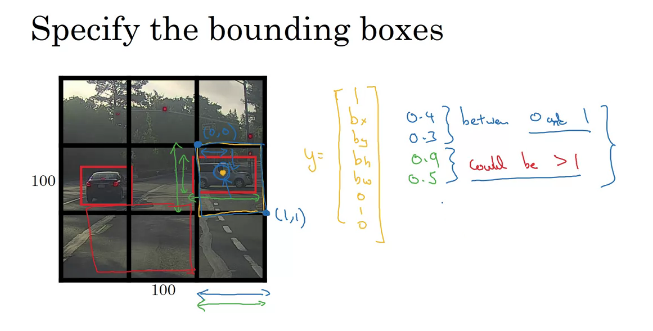
- label vector는 그리드에 대해서 상대적으로 주어진다는 점이 중요하다.
- grid cell의 top-left를 좌표(0,0), bottom-right를 좌표(1,1)로 지정하고 그것에 상대적으로 object의 중심점에 대해 좌표
\(bx,by\) bh,bw - object의 중심점이 grid 내부에 있기 때문에
bx,by - object가 여러 grid에 걸쳐 bboxing이 되어있을 수 있으므로
bh,bw
2. 2 IOU(Intersection Over Union)

predicted box와 ground truth box에 대해, IOU란 전체 size 대비해 서로 어느정도 겹치는가를 나타낸다. 즉, 예측된 결과가 얼마나 실제 값과 매치되는가를 나타내는 지표.
보통
2.3 Non-max Suppression
grid를 나누고 object의 중심과 그에 따른 bounding box를 grid 찾을 때, 모든 분할 grid 셀들 각각에 대해 object classification과 localization 알고리즘을 실행하고 있으므로 여러 그리드에서 객체의 중심이 여기에 있다라고 예측할 수 있다.
즉 한 객체에 대해 여러 grid cell에서 bounding box가 생겨날 수 있다.
Non-max Suppression은 이렇게 생긴 여러 bounding box를 한 객체에 대해 하나만 남도록 해주는 알고리즘이다.

위를 예제로 Non-max suppression의 동작을 살펴보자.
- 먼저 모든 grid cell에서 구해진 pc 값을 보고, 이 값이 일정 threshold(보통 0.6)보다 낮으면 그 box들을 제거한다.
- 다음으로 남은 box들 중에서 가장 Pc가 높은 box를 찾는다.
- 찾은 box와의 IOU가 일정수준이 넘는 box들을 찾아 제거한다.
- 마지막으로 남아있는 box들 중에서 가장 높은 Pc를 가지는 box를 찾고 위 2번 과정을 반복한다.
위의 예제는 class가 1개일 경우이고, 만약 class가 n개인 detection을 한다면 Non-max suppression을 각 클래스에 대해 독립적으로(n회) 수행하여야 한다.
2.4 Anchor box
object detection의 문제점
- 오직 한 grid cell에 대해 한 object만 감지 할 수 있다.
- 이러한 점을 해결하기 위해 anchor box를 사용.
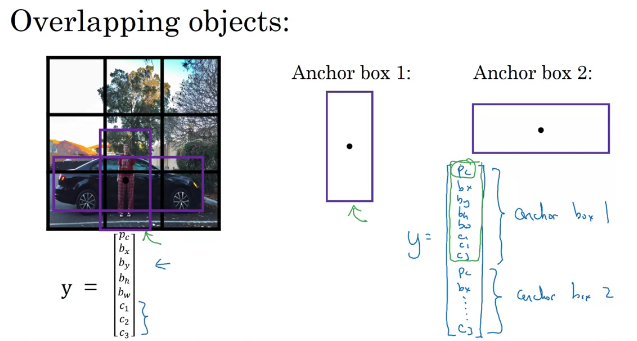
- 한 grid cell에 여러 객체의 중심이 있을 수 있다.
- 그럴 경우 anchor box를 활용해 두 객체에 대한 bounding box를 예측할 수 있다.
- 먼저 anchor box의 개수와 비율을 정한다.
- grid cell에서 예측을 할 때, 위의 예제의 경우 class를 pedestrian과 car 두 개라고 본다면, pedestrian의 모양이 anchor box2보다 1과 더 유사하므로 label을 pedestrian에 대해 encoding하고, car의 모양은 2와 더 유사하므로 label을 car에 대해 encoding 한다.
- 한 grid cell에 두 개의 객체에 대한 detect.
- 유사도는 IOU를 통해 판단. 즉, ground truth와 가장 유사한 모양을 가지는 anchor box.
- 만약 위 예제에서 car만 있는 경우, anchor box1부분은 pc부분이 0이 되고 나머지는 무시하도록 되어질 것이다.
anchor box의 한계
- anchor box는 2개인데 한 grid cell에 3개의 객체가 있을 경우 잘 처리하지 못한다.
- 한 grid cell에 두 object가 있는데 둘 다 똑같은 anchor box모양을 가지고 있는 경우도 잘 처리하지 못한다.
Reference
'인공지능 > 딥러닝 모델' 카테고리의 다른 글
| [분류모델] ResNet (0) | 2021.06.28 |
|---|---|
| [분류모델] VGGNET (0) | 2021.06.24 |