2022. 1. 24. 20:32ㆍ논문리뷰/GAN
이번에는 한국에서 낸 유명한 GAN논문인 StarGAN을 리뷰할 것이다.
https://arxiv.org/abs/1711.09020
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for eve
arxiv.org
기존 방식들은 2개의 domain간의 translation을 다뤘다면 이 논문에서는 다수의 domain 간의 translation을 목표로 하고 있다. 어떤 문제가 있었고, 어떻게 해결하였는지 살펴보도록 하자!

1. Image-to-image Translation

image-to-image translation이란, 어떤 이미지의 양상, 쉽게 말해 특징,을 또 다른 양상으로 바꾸는 task를 말한다. 예를 들면, 어떤 사람의 피부색을 바꾼다거나 표정을 바꾸는 등의 얼굴의 어떠한 특징을 다른 특징으로 바꿀 수 있을 것이다.
이러한 image-to-image translation은 GAN이 등장하면서 매우 큰 성능 향상을 이루었다. Generative Adversarial Training이 실제로 있을 법한 image를 만들어내는데 뛰어나기 때문에 이미지 간의 translation이 최대한 자연스럽게 이루어질 수 있기 때문이다.
2. Problem of tranditional method
이전의 GAN-based method로 유명한 몇 가지 예를 간단하게 살펴보고 어떠한 문제점이 있는지 알아보자.
2.1 pix2pix
출처: https://phillipi.github.io/pix2pix/
pix2pix는 어떠한 이미지를 condition으로 주고 그에 따른 translation을 만들어내는 일종의 CGAN방식을 사용한다. 위처럼 object의 간략한 스케치 이미지를 주었을 때, 이에 맞는 실제 object와 비슷한 결과 이미지를 출력한다.
하지만 이 방식은 학습할 때 pair image를 알고 있어야한다는 단점이 있다. 즉, 위의 고양이 스케치와 매칭되는 실제 고양이 이미지 pair 데이터셋을 만들 필요가 있고, 이는 시간적으로나 비용적으로나 매우 비싸다. 어떤 도메인에서는 이러한 pair를 만들어내는 것 자체가 불가능할 수 도 있다.
2.2 CycleGAN
출처: https://machinelearningmastery.com/cyclegan-tutorial-with-keras/
위와 같은 문제점을 해결하기 위해 CycleGAN이 등장한다.
만약 pair imageset이 아닌 이미지 간 translation을 이전과 같은 방식으로 하게 되면, 기존 이미지의 structual한 특징들이 뭉뚱그려져서 그려질 수도 있고, 하나의 이미지 변환만을 잘 배워서 그 이미지만 결과로 내보내어 버리는 문제가 생길 수 있다.
CycleGAN에서는 이러한 문제를 해결하기 위해 Cycle Loss를 사용한다. 방법은 간단히 domain A와 domain B가 있다고 할 때(위 이미지에서 말이 domain A, 얼룩말이 domain B), CycleGAN은 A->B로 변환하고, 그 이미지를 다시 B->A로 Reconstruction하는 것이다.
즉, 변환된 이미지가 다시 원래의 이미지로 돌아올 수 있도록 제한을 줌으로써 어떠한 한 이미지에 국한되는 것이 아니라 해당하는 이미지의 structure한 정보는 가져가면서 변하길 원하는 domain간의 translation만 이루어지도록 하는 것이다.
하지만 CycleGAN은 두 domain간의 translation을 위해 2개의 Generator를 사용한다.
2.3 더 많은 domain 간의 학습은?
위에서 말했듯이 2가지 domain에 대해서는 2개의 generator, 이론적으로 4개의 domain 간 translation을 배우기 위해서는 12개의 generator가 필요하다. 이런 방식은 memory적으로나 computation cost로나 매우 비효율적이고, 두 domain간의 generators끼리만 데이터를 공유하기 때문에 학습에서도 비효율적일 수 밖에 없다.
이러한 multi-domain에서의 translation을 한 generator만을 사용하여 학습하고자 하는 것이 StarGAN이다.
3. StarGAN
StarGAN은 다수의 Domain 간의 translation을 한 generator로 학습시키기 위와 같은 모델 architecture를 가진다.
먼저 간단하게 전체적인 training 과정을 살펴보고 loss에 대해서 알아보자.
Generator
- 먼저, input으로는 image 뿐만 아니라 target domain label을 같이 넣어준다. 이 target label은 random하게 생성되어 input image를 flexeble하게 translate하도록 한다.
- 두번째로, 같은 generator(G)를 사용하여 CycleGAN의 형태를 사용한다. 즉, target domain label에 해당하는 이미지로 변환한 다음에 다시 원래 domain label에 해당하는 이미지로 reconstruction한다. 일반 CycleGAN과 다른 점은 generator를 공통으로 하나만 사용한다는 점이다.
- 마지막으로, 만들어진 이미지는 Discriminator(D)에 input으로 입력되고 generated image가 real이 되도록, 또 target label이 분류모델을 통해 나오도록 학습이된다.
Discriminator
- Ground-Truth image와 Generated Image를 input으로 받는다.
- 이전과 같이 real image와 fake image를 구별하고, 실제 이미지의 domain label이 나오도록 분류모델을 학습한다.
Conditional Input
사설로 target domain label과 input image가 어떤식으로 concat 되는지 설명하고자 한다. 논문에는 따로 기재되어 있지 않은데 github를 보고서 해석한 것이라 문제가 있다면 말해주길 바란다.
- 먼저 target domain label을 1x12차원 vector(5: celebA, 5: ReFD, 2: mask vector), input image를 1x3x64x64 tensor라 가정해보자.
- 그 다음 target domain label을 1x1 tensor로 reshape한다.
1x12−>1x12x1x1 - 그리고 이 1x1 tensor를 이미지의 width, height크기로 repeat한다.
1x12x1x1−>1x12x64x64 - 마지막으로 이 tensor와 input image를 depth-wise concat한다.
1x12x64x64+1x3x64x64−>1x15x64x64
즉, 간단하게 말해서 모든 pixel의 rgb채널에 target label을 concat해주는 것이라고 생각하면 된다.
3.1 Loss
이제 사용된 loss들을 보면서 더 자세한 학습 과정을 살펴보려고 한다. StarGAN에서는 adversarial loss, domain classification loss, reconstruction loss 총 3가지의 loss가 사용된다.
Adversarial Loss
adversarial loss는 conditional information인 target domain label c를 제외하고 이전과 똑같다.
간단하게 Generator G는 최대한 ground-truth와 비슷한 이미지를 만들어서 Discriminator D를 속이도록 학습을 하고, Discriminator D는 Generator G에서 생성된 fake image와 real image를 구별할 수 있도록 학습하게 된다.
Domain Classification Loss
이는 Generator G와 Discriminator D 학습에 따라 2가지로 나누어지는데, input image x가 domain c에 해당하는 이미지로 잘 변환될 수 있도록 하는 Loss term이다.
먼저 Discriminator를 학습할 경우에는, real image
다음으로 Generator를 학습할 때는, Generated image가 target label c로 분류되도록 학습이 된다.
Reconstruction Loss
Reconstruction loss로는 Cycle loss를 사용한다. 하나 다른 점은 한 개의 Generator를 사용한다는 점이고, 이는 이전에 설명했던 것처럼 domain 간 translation에서 input의 content는 보존하면서 domain-related 부분만 변하게 하기 위해 사용된다. metric으로는 L1 norm을 사용한다.
최종적인 Loss는 다음과 같다.
**
Addictive Information
추가적으로 Adversarial loss를 training process를 stabilize하고, higher quality 이미지들 generate하기 위해서 WGAN-GP의 gradient penalty를 적용한 식으로 바꾸어 사용한다. 더 자세한 내용은 WGAN과 WGAN-GP 논문을 읽어보길 바란다.
3.2 Training with Multiple Datasets
StarGAN의 또 다른 장점은 다른 label type을 가지는 여러 데이터셋들을 동시에 사용할 수 있다는 것이다.
여러 데이터셋을 사용할 수 있다면 데이터의 수가 비약적으로 많아지므로 당연히 좋은 성능이 나올 확률이 높아지게 된다. 하지만 데이터셋마다 가지고 있는 attribute의 정보가 다르므로 문제가 생길 수 있다.
**예를들어, CelebA는 hair color, gender와 같은 외형에 관한 attribute, RaFD는 happy, angry와 같은 감정적인 attribute를 가지고 있고 서로의 label은 다른 데이터셋의 attribute를 포함하고 있지 않다.
Mask Vector
그래서 이 논문에서는 Mask Vector라는, 데이터셋을 구분하는 vector를 추가로 concat해서 이러한 문제를 해결한다.
방법은 매우 간단하다 이미지의 label을 줄 때, 모든 속성들에 대한 vector와 mask vector를 단순히 이어붙이는 것이다.
예를 들어, CelebA는 "black", "blond", "brown", "male", "young" attribute를 가지고, RaFD는 "angry", "fearful", "happy", "sad", "disgusted"를 가지고 있다. 내가 금발의 젊은 여성의 이미지를 input으로 준다고 하면, ground truth label은 CelebA label: [0, 1, 0, 0, 1] + RaFD label: [0, 0, 0, 0, 0] + mask vector: [1, 0]이 된다. 여기서 +는 concat이고, 0과 1은 각 속성의 on/off를 나타내며 mask vector의 속성은 ["celebA", "RaFD"]라고 생각하면 된다.
이렇게 만듦으로써, StarGAN이 unspecified labels를 무시하고, 특정 데이터셋에서 주어진 explicitly known label에 대해서만 집중하여 학습하도록 한다.
4. Experiments

이 part에서는 StarGAN과 CelebA와 RaFD데이터셋을 사용하여 학습시킨 다른 Image-to-image Translation 기법들(DIAT, CycleGAN, IcGAN)을 비교하여 실험한 결과를 보여준다. 더 자세한 네트워크 구조와 hyper-parmeter들을 알고 싶다면 논문을 참조하기 바란다.
먼저 위 이미지를 살펴보면 StarGAN이 다른 method에 비해 image quality가 훨씬 좋은 것을 알 수 있다. 이는 multi-domain에 대해서 2개의 Domain에 한정해서만 Generator를 공유하는(즉, domain에 따라 쓸 수 있는 데이터셋이 한정된다) 다른 기법들에 비해, StarGAN은 모든 데이터셋을 사용하여 하나의 Generator로 학습을 하기 때문에 데이터의 수에서 이득을 취하게 되고, 이는 domain 외의 얼굴의 윤곽이나 다른 detail을 더 잘 나타내는 강점을 가지게 된다.

이 예는 StarGAN을 RaFD 데이터셋만 학습시킨 모델(상단)과 RaFD와 CelebA 데이터셋을 joint로 학습시킨 모델(하단)의 결과를 비교한 이미지이다. 위에서 이야기하였던 것처럼 같은 이미지에 대해서, 두 데이터셋을 모두 사용하였을 때의 모델이 더 detail한 feature를 잘 살려내는 것을 볼 수 있다.
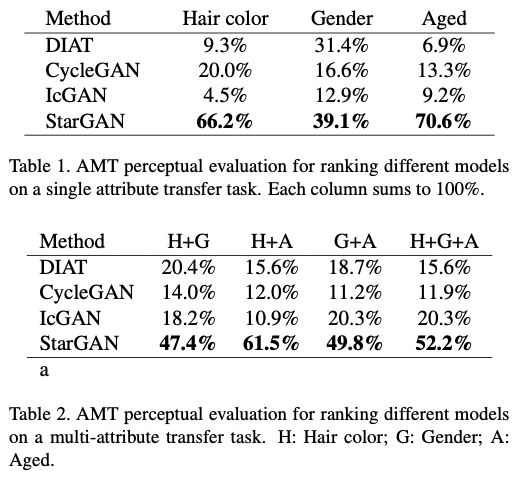
quantitative한 평가는 Amazon Mechanical Turk를 이용한 survey를 통해 이루어졌다. 자세한 설명은 논문에서 참조하길 바란다. 결과만 보자면, 대다수의 사람들이 다른 method에 의해 생성된 이미지들보다 StarGAN이 만든 이미지가 더 perceptual하다고 평가하였다.
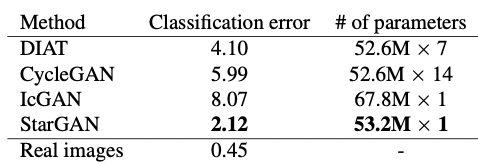
parameter 측면에서도 StarGAN이 다른 모델에 비해 매우 적은 수를 가지고 있다는 것을 알 수 있다.
이렇게 StarGAN에 대한 내용을 살펴보았다. 얼굴 데이터를 사용하여 multi-domain translation을 한 결과는 솔직히 놀라웠다. 한번에 여러 domain으로 translation할 수 있다는 것과 한 개의 generator만 사용한다는 점은 큰 merit라고 말할 수 있다.
하지만 몇 가지 의문점도 있다. 얼굴 데이터야 서로 공통된 부분이 많으니까 잘 되는 것이 아닐까? 그리고 github에서 제공하는 code와 model을 사용하여 test해보았을 때, 논문만큼 성능이 나오지 않는다(어찌보면 당연...). 완전히 다른 attribute에 해당하는 데이터셋들로 학습했을 때는 성능이 확연히 떨어지지 않을까 하는 생각이 들고, 또한 논문에서 multiple datasets을 사용할 수 있다하고서 2개의 데이터셋만 사용하는 걸로 보아 multiple datasets에 대한 성능도 의심이 든다.
그래도 이 논문에 대한 가장 큰 contribute는 multi-domain translation을 하나의 generator로 한정된 데이터셋이라 하더라도 성공하였다는 것이니까 넘어가도록 하자.
'논문리뷰 > GAN' 카테고리의 다른 글
| [논문 리뷰] Pix2Pix: Image-to-Image Translation with CGAN (0) | 2022.05.22 |
|---|---|
| [논문리뷰] Unsupervised Pixel-level Domain Adaptation with GAN (0) | 2022.02.28 |
| [논문 리뷰] Multimodal Unsupervised Image-to-Image Translation (0) | 2022.02.22 |
| [논문리뷰] Perceptual Adversarial Networks for Image-to-Image Transformation (0) | 2022.01.18 |